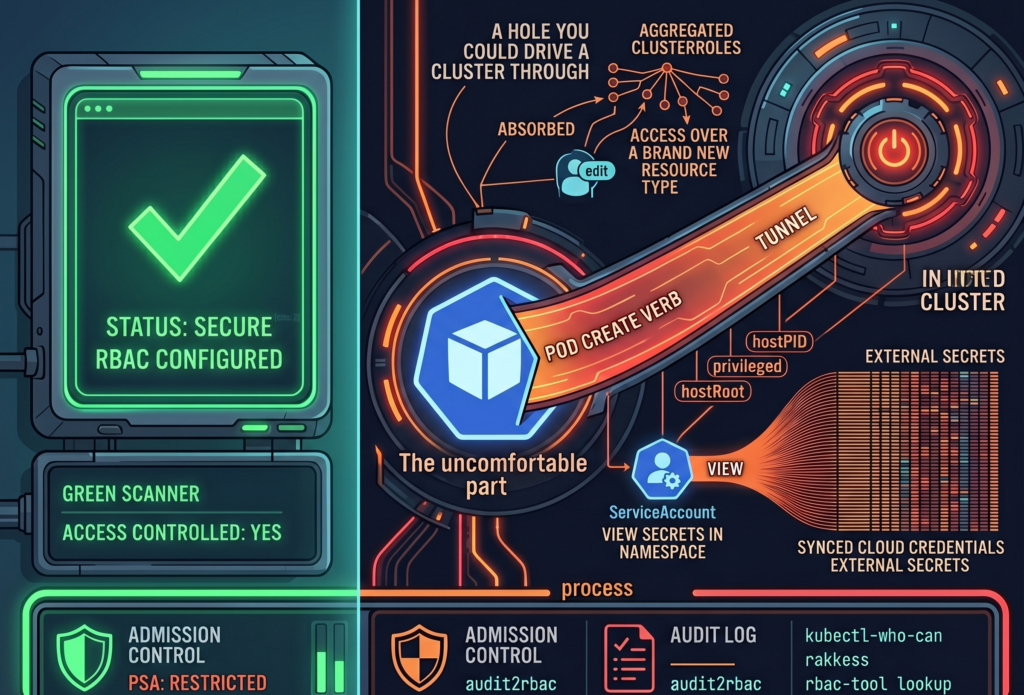
Your security scanner ran last night. It came back green. RBAC is configured, there are no critical findings, and you closed the tab with the quiet satisfaction of someone who has done the responsible thing. The cluster is locked down. You can go to lunch.
Here is the uncomfortable part. A green scanner answers the question “Is access controlled?” It does not answer the question “Is access minimal?” Those are different questions, and most teams conflate them because the first one is easy to check and the second one requires reading things nobody wants to read on a Tuesday.
RBAC answers the first. Least privilege requires answering both. And a perfectly valid RBAC configuration can be, at the very same time, a perfectly generous one. The scanner has no opinion about generosity.
The ClusterRole you inherited from a Helm chart in March
Kubernetes ships three aggregated ClusterRoles out of the box (admin, edit, view), and they have a quietly alarming property. They absorb permissions. Any ClusterRole carrying the label ‘rbac.authorization.k8s.io/aggregate-to-edit: “true”’ gets automatically folded into ‘edit’, with no human in the loop and no diff to review.
This is convenient right up until it is not. When you installed that operator back in March, its Helm chart shipped a CRD and a ClusterRole with the aggregation label attached, because that is the polite, idiomatic way to do it. From the moment ‘helm install’ finished, every subject bound to ‘edit’ in your cluster silently gained permissions over a brand new resource type. Nobody approved it. Nobody saw it. The controller did exactly what it was designed to do, which is the part that should worry you.
So the RoleBinding still says ‘edit’. The word has not changed. What it grants has, several times, across several chart upgrades, and the only record of the expansion is scattered across ClusterRole objects nobody has opened since they were applied.
The takeaway is small and annoying: every time you install a chart, check what it aggregated. ‘kubectl get clusterrole -l rbac.authorization.k8s.io/aggregate-to-edit=true’ is two minutes of your life and occasionally a genuine surprise.
That ServiceAccount reads secrets, all of them, probably
Consider a ServiceAccount with ‘get’ on secrets in a single namespace. On paper, this looks narrow and tidy. The reviewer who approved it was right to approve it. The problem is that RBAC grants do not live in isolation; they live next to whatever else is running in that namespace.
If that namespace also hosts External Secrets Operator, a Vault Agent sidecar, or a CSI secrets driver, the secrets sitting there are not application trivia. They are the synced, materialized credentials that those tools pulled from somewhere more important. A grant that reads “can view secrets in ‘team-a’” can, depending on the architecture around it, mean “can read the cloud provider credentials that External Secrets faithfully copied into ‘team-a’ thirty seconds ago.”
Nothing here is broken. Every component is behaving as documented. That is exactly why it slips past review: each piece is reasonable, and the risk only exists in the seam between them, where no single Role definition is looking.
So when you audit a secrets grant, do not read the Role. Read the room. Ask what else lives in that namespace and what those neighbors keep in their pockets.
Creating a Pod sometimes creates a root shell on the node
This is the one people refuse to believe until you show them.
If Pod Security Admission is not enforced in ‘restricted’ mode, a subject with ‘create’ on pods is, functionally, a subject with a path to the node. They can define a pod that mounts the host root filesystem as a volume, sets ‘hostPID: true’, runs ‘privileged: true’, or maps a host port to quietly intercept traffic. From inside that pod, the node is no longer a node; it is a directory.
None of this is a vulnerability. There is no CVE to patch, because Kubernetes is doing precisely what the spec permits. The escalation lives in the gap between two true statements: “we have RBAC” and “nobody can reach the node.” Both can be accurate. Together, they can still be a hole you could drive a cluster through.
The fix is not more RBAC. It is admission control. Enforce PSA ‘restricted’ as the namespace default, and treat every exception as a decision someone wrote down and owns, rather than a default nobody chose.
Three commands that will ruin your afternoon
Theory is comfortable. Here is the part where you actually look.
‘kubectl-who-can’ answers the blunt question: who can perform this verb on this resource, right now. ‘kubectl who-can create pods -n production’ is a fast way to find out that the list is longer than you remembered.
‘rakkess’ produces a full access matrix for a given subject, so you can stare at an entire grid of green checkmarks belonging to a ServiceAccount that, in principle, only needed to read a config map.
‘rbac-tool lookup’ lists everything a specific subject can do across the whole cluster, which is the tool you run when you have a name and a bad feeling.
I will set an honest expectation. The first time you run any of these against a cluster older than a year, you will find at least one thing nobody intended, and there is a decent chance it will be something you granted. This is not a moral failing. It is entropy. Permissions accrete the same way junk drawers do, one reasonable decision at a time.
The scanner will still be green, that is no longer the point
Here is where I am supposed to hand you a fix that makes the scary parts go away. I cannot, because least privilege in Kubernetes is not a configuration state you reach and then defend. It is a process you keep doing, slightly grudgingly, forever.
Start subjects at zero and grant only what the audit log proves they actually use. Tools like ‘audit2rbac’ can generate tight RBAC from real API server audit events, which is to say from evidence rather than from optimism. Enforce PSA ‘restricted’ by default. Audit aggregated ClusterRoles every time you install a chart. Rotate ServiceAccount tokens, because a credential that never expires is just a future incident with good patience.
Do all of that, and run the scanner again. It will still be green. It was always going to be green. The result has not changed at all. The only thing that has changed is the question you now know to ask, and that, inconveniently, was the whole job.
There is no universal answer here, only better-informed trade-offs, and the faint suspicion that your next audit will find something too. It usually does.