In the era of data-driven decision-making, organizations must efficiently handle and analyze immense volumes of data in real-time to maintain a competitive edge. As an AWS Solutions Architect, one of the critical tasks you may encounter is designing an architecture that can efficiently handle the ingestion, processing, and analysis of large datasets as they stream in from various sources. The goal is to ensure that the solution is scalable and capable of delivering high performance consistently, regardless of the data volume.
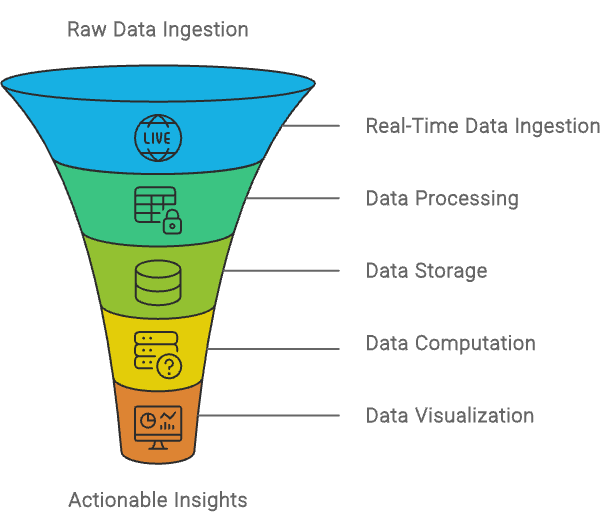
Building the Foundation. Real-Time Data Ingestion
The journey begins with the ingestion of data. When data streams continuously from multiple sources, such as application logs, user interactions, and IoT devices, it’s essential to use a service that can handle this flow with minimal latency. Amazon Kinesis Data Streams is the ideal choice here. Kinesis is engineered to handle real-time data ingestion at scale, allowing you to capture and process data as it arrives, with low latency. Its ability to scale dynamically ensures that your system remains robust no matter the surge in data volume.
Processing Data in Real-Time. The Power of Serverless
Once the data is ingested, the next step is real-time processing. This is where AWS Lambda shines. Lambda allows you to run code in response to events without provisioning or managing servers. As data flows through Kinesis, Lambda can be triggered to process each chunk of data, applying necessary transformations, filtering, and even enriching the data on the fly. The serverless nature of Lambda means it automatically scales with your data, processing millions of records without any manual intervention, which is crucial for maintaining a seamless and responsive architecture.
Storing Processed Data. Durability Meets Scalability
After processing, the transformed data needs to be stored in a way that it is both durable and easily accessible for future analysis. Amazon S3 is the backbone of storage in this architecture. With its virtually unlimited storage capacity and high durability, S3 ensures that your data is safe and readily available. For those more complex analytical queries, Amazon Redshift serves as a powerful data warehouse. Redshift allows for efficient querying of large datasets, enabling quick insights from your processed data. By separating storage (S3) and compute (Redshift), the architecture leverages the best of both worlds: cost-effective storage and powerful analytics.
Visualizing Data. Turning Insights into Action
Data, no matter how well processed, is only valuable when it can be turned into actionable insights. Amazon QuickSight provides an intuitive platform for stakeholders to interact with the data through dashboards and visualizations. QuickSight seamlessly integrates with Redshift and S3, making it easy to visualize data in real-time. This empowers decision-makers to monitor key metrics, observe trends, and respond to changes with agility.
Optimizing for Scalability and Cost-Efficiency
Scalability is a cornerstone of this architecture. By leveraging AWS’s built-in scaling features, services like Amazon Kinesis and Redshift can automatically adjust to fluctuations in data volume. For Amazon Kinesis, enabling Kinesis Data Streams On-Demand ensures that the architecture scales out to handle higher loads during peak times and scales in during quieter periods, optimizing costs without manual intervention. Similarly, Amazon Redshift uses Concurrency Scaling to handle spikes in query load by adding additional compute resources as needed, and Elastic Resize allows the infrastructure to dynamically adjust storage and compute capacity. These auto-scaling mechanisms ensure that the infrastructure remains both cost-effective and high-performing, regardless of the data throughput.
How the Services Work Together
The true strength of this architecture lies in the seamless integration of AWS services, each contributing to a robust, scalable, and efficient big data solution. The journey begins with Amazon Kinesis Data Streams, which captures and ingests data in real-time from various sources. This real-time ingestion ensures that data flows into the system with minimal latency, ready for immediate processing.
AWS Lambda steps in next, automatically processing this data as it arrives. Lambda’s serverless nature allows it to scale dynamically with the incoming data, applying necessary transformations, filtering, and enrichment. This immediate processing ensures that the data is in the right format and enriched with relevant information before moving on to the next stage.
The processed data is then stored in Amazon S3, which serves not only as a scalable and durable storage solution but also as the foundation of a Data Lake. In a big data architecture, a Data Lake on S3 acts as a centralized repository where both raw and processed data can be stored, regardless of format or structure. This flexibility allows for diverse datasets to be ingested, stored, and analyzed over time. By leveraging S3 as a Data Lake, the architecture supports long-term storage and future-proofing, enabling advanced analytics and machine learning applications on historical data.
Amazon Redshift integrates seamlessly with this Data Lake, pulling in the processed data from S3 for complex analytical queries. The synergy between S3 and Redshift ensures that data can be accessed and analyzed efficiently, with Redshift providing the computational power needed for deep dives into large datasets. This capability allows organizations to derive meaningful insights from their data, turning raw information into actionable business intelligence.
Finally, Amazon QuickSight adds a layer of accessibility to this architecture. By connecting directly to both S3 and Redshift, QuickSight enables real-time data visualization, allowing stakeholders to interact with the data through intuitive dashboards. This visualization is not just the final step in the data pipeline but a crucial component that transforms data into strategic insights, driving informed decision-making across the organization.
Basically
The architecture designed here showcases the power and flexibility of AWS in handling big data challenges. By utilizing services like Kinesis, Lambda, S3, Redshift, and QuickSight, you can build a solution that not only processes and analyzes data in real-time but also scales automatically to meet the demands of any situation. This design empowers organizations to make data-driven decisions faster, providing a competitive edge in today’s fast-paced environment. With AWS, the possibilities for innovation in big data are endless.
