Let’s jump into a topic that is gaining importance in the world of DevOps and Site Reliability Engineering (SRE): incident management and blameless postmortems. Now, I know these terms might seem a bit intimidating at first, but don’t worry, we’re going to break them down in a way that’s easy to grasp. So, grab a cup of coffee (or your favorite beverage), and let’s explore these critical skills together.
1. Introduction. Why Is Incident Management Such a Big Deal?
Imagine you’re piloting a spaceship through uncharted territory. Suddenly, a red warning light starts flashing. What do you do? Panic? Start pressing random buttons? Of course not! You want a well-rehearsed plan, right? That’s essentially what incident management is all about in the tech world.
Unexpected issues might arise in today’s rapid digital environment, much like that red light on your spaceship’s dashboard. Users become irate when websites crash and services are unavailable. The methodical approach known as incident management enables teams to respond to these issues promptly and effectively, reducing downtime and expediting the restoration of service.
But what does this have to do with DevOps and SRE? Well, if DevOps and SRE professionals are the astronauts of the tech world, then incident management is their emergency survival training. And it’s becoming more and more essential as companies recognize how critical it is to keep their services running smoothly.
2. Incident Management. Keeping the Digital Spaceship Afloat
Sticking with our spaceship analogy, a small issue in space can quickly spiral out of control if not managed properly. Similarly, a minor glitch in a digital service can escalate into a major outage if the response isn’t swift and effective. That’s where incident management shines in DevOps and SRE.
Effective incident management is like having a well-practiced, automatic response when things go wrong. It’s the difference between panicking and pressing all the wrong buttons, or calmly addressing the issue while minimizing damage. Here’s how the process generally unfolds:
- Incident Detection and Alerting: Think of this as your spaceship’s radar. It constantly scans for anomalies and sounds the alarm when something isn’t right.
- Incident Response and Triage: Once the alert goes off, it’s time for action! This step is like diagnosing a patient in the ER – figuring out the severity of the situation and the best course of action.
- Incident Resolution and Communication: Now it’s time to fix the problem. But equally important is keeping everyone informed – from your team to your customers, about what’s happening.
- Post-Incident Analysis and Documentation: After things calm down, it’s time to analyze what happened, why it happened, and how to prevent it from happening again. This is where blameless postmortems come into play.
3. Blameless Postmortems. Learning from Mistakes Without the Blame Game
Now, let’s talk about blameless postmortems. The idea might sound strange at first, but “postmortem” usually refers to an examination after death, right? In this context, however, a postmortem is simply an analysis of what went wrong during an incident.
The key here is the word “blameless.” Instead of pointing fingers and assigning blame, the goal of a blameless postmortem is to learn from mistakes and figure out how to improve in the future. It’s like a sports team reviewing a lost game, instead of blaming the goalkeeper for missing a save, the entire team looks at how they can play better together next time.
So, why is this approach so effective?
- Encourages open communication: When people don’t fear blame, they’re more willing to be honest about what happened.
- Promotes continuous learning: By focusing on improvement rather than punishment, teams grow and become stronger over time.
- Prevents repeat incidents: The deeper you understand what went wrong, the better you can prevent similar incidents in the future.
- Builds trust and psychological safety: When team members know they won’t be scapegoated, they’re more willing to take risks and innovate.
4. How to Conduct a Blameless Postmortem.
So, how exactly do you conduct a blameless postmortem?
- Gather all the facts: First, collect all relevant data about the incident. Think of yourself as a detective gathering clues to solve a mystery.
- Assemble a diverse team: Get input from different parts of the organization. The more perspectives, the better your understanding of what went wrong.
- Create a safe environment: Make it clear that this is a blame-free zone. The focus is on learning, not blaming.
- Identify the root cause: Don’t stop at what happened. Keep asking “why” until you get to the core of the issue.
- Brainstorm improvements: Once the root cause is identified, think about ways to prevent the problem from recurring. Encourage creative solutions.
- Document and share: Write everything down and share it with your team. Knowledge is most valuable when it’s shared.
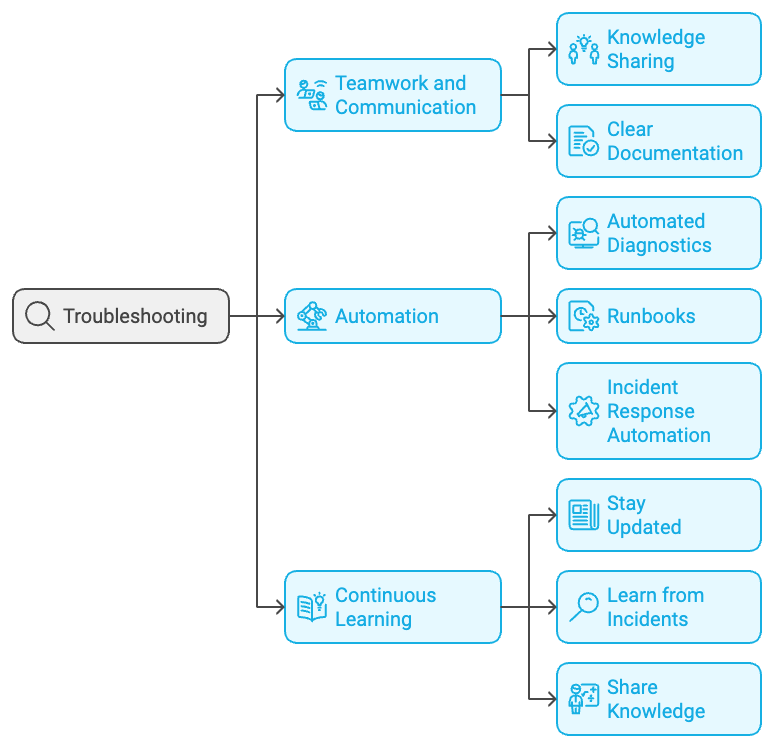
5. Best Practices for Incident Management and Blameless Postmortems
Now that you understand the basics, let’s look at some tips to take your incident management and postmortems to the next level:
- Invest in automation: Use tools that can detect and respond to incidents quickly. It’s like giving your spaceship an AI co-pilot to help monitor the systems in real-time.
- Define clear roles: During an incident, everyone should know their specific responsibility. This prevents chaos and ensures a more coordinated response.
- Foster transparency: Be honest about incidents, both internally and with your customers. Transparency builds trust, and trust is key to customer satisfaction.
- Regularly review and refine: The tech landscape is always changing, so your incident management processes should evolve too. Keep reviewing and improving them.
- Celebrate successes: When your team handles an incident well, take the time to recognize their effort. Celebrating successes reinforces positive behavior and keeps morale high.
6. Embracing a Journey of Continuous Improvement
We have taken a journey through the fascinating world of incident management and blameless postmortems. It’s more than just a skill for the job, it’s a mindset that fosters continuous improvement.
Mastering these practices is key to becoming an exceptional DevOps or SRE professional. But more importantly, it’s about adopting a philosophy of learning from every incident, evolving from every mistake, and pushing our digital spaceships to fly higher and higher.
So, the next time something goes wrong, remember: it’s not just an incident, it’s an opportunity to learn, grow, and get even better. After all, isn’t that what continuous improvement is all about?