
Containers behave perfectly until you check their pockets. Then you find an elderly OpenSSL and a handful of dusty transitive dependencies that they swore they did not know. Docker Scout is the friend who quietly pats them down at the door, lists what they are carrying, and whispers what to swap so the party does not end with a security incident.
This article is a field guide for getting value from Docker Scout without drowning readers in output dumps. It keeps the code light, focuses on practical moves, and uses everyday analogies instead of cosmic prophecy. By the end, you will have a small set of habits that reduce late‑night pages and cut vulnerability noise to size.
Why scanners overwhelm and what to keep
Most scanners are fantastic at finding problems and terrible at helping you fix the right ones first. You get a laundry basket full of CVEs, you sort by severity, and somehow the pile never shrinks. What you actually need is:
- Context plus action: show the issues and show exactly what to change, especially base images.
- Comparison across builds: did this PR make things better or worse?
- A tidy SBOM: not a PDF doorstop, an artifact you can diff and feed into tooling.
Docker Scout leans into those bits. It plugs into the Docker tools you already use, gives you short summaries when you need them, and longer receipts when auditors appear.
What Docker Scout actually gives you
- Quick risk snapshot with counts by severity and a plain‑language hint if a base image refresh will clear most of the mess.
- Targeted recommendations that say “move from X to Y” rather than “good luck with 73 Mediums.”
- Side‑by‑side comparisons so you can fail a PR only when it truly regresses security.
- SBOM on demand in useful formats for compliance and diffs.
That mix turns CVE management from whack‑a‑mole into something closer to doing the dishes with a proper rack. The plates dry, nothing falls on the floor, and you get your counter space back.
A five-minute tour
Keep this section handy. It is the minimum set of commands that deliver outsized value.
# 1) Snapshot risk and spot low‑hanging fruit
# Tip: use a concrete tag to keep comparisons honest
docker scout quickview acme/web:1.4.2
# 2) See only the work that unblocks a release
# Critical and High issues that already have fixes
docker scout cves acme/web:1.4.2 \
--only-severities critical,high \
--only-fixed
# 3) Ask for the shortest path to green
# Often this is just a base image refresh
docker scout recommendations acme/web:1.4.2
# 4) Check whether a PR helps or hurts
# Fail the check only if the new image is riskier
docker scout compare acme/web:1.4.1 --to acme/web:1.4.2
# 5) Produce an SBOM you can diff and archive
docker scout sbom acme/web:1.4.2 --format cyclonedx-json > sbom.jsonPro tip
Run QuickView first, follow it with recommendations, and treat Compare as your gate. This sequence removes bikeshedding from PR reviews.
One small diagram to keep in your head
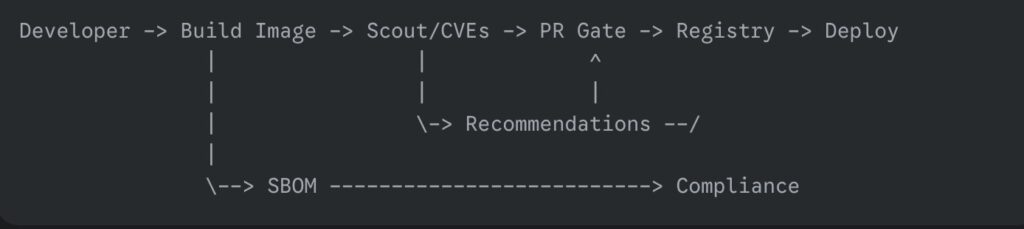
Nothing exotic here. You do not need a new mental model, only a couple of strategic checks where they hurt the least.
A pull request check that is sharp but kind
You want security to act like a seatbelt, not a speed bump. The workflow below uploads findings to GitHub Code Scanning for visibility and uses a comparison gate so PRs only fail when risk goes up.
name: Container Security
on: [pull_request, push]
jobs:
scout:
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
security-events: write # upload SARIF
steps:
- uses: actions/checkout@v4
- name: Login to Docker Hub
uses: docker/login-action@v3
with:
username: ${{ secrets.DOCKERHUB_USERNAME }}
password: ${{ secrets.DOCKERHUB_TOKEN }}
- name: Build image
run: |
docker build -t ghcr.io/acme/web:${{ github.sha }} .
- name: Analyze CVEs and upload SARIF
uses: docker/scout-action@v1
with:
command: cves
image: ghcr.io/acme/web:${{ github.sha }}
only-severities: critical,high
only-fixed: true
sarif-file: scout.sarif
- name: Upload SARIF to Code Scanning
uses: github/codeql-action/upload-sarif@v3
with:
sarif_file: scout.sarif
- name: Compare against latest and fail on regression
if: github.event_name == 'pull_request'
uses: docker/scout-action@v1
with:
command: compare
image: ghcr.io/acme/web:${{ github.sha }}
to-latest: true
exit-on: vulnerability
only-severities: critical,highWhy this works:
- SARIF lands in Code Scanning, so the whole team sees issues inline.
- The compare step keeps momentum. If the PR makes the risk lower than or equal to, it passes. If it makes things worse at High or Critical, it fails.
- The gate is opinionated about fixed issues, which are the ones you can actually do something about today.
Triage that scales beyond one heroic afternoon
People love big vulnerability cleanups the way they love moving house. It feels productive for a day, and then you are exhausted, and the boxes creep back in. Try this instead:
Set a simple SLA
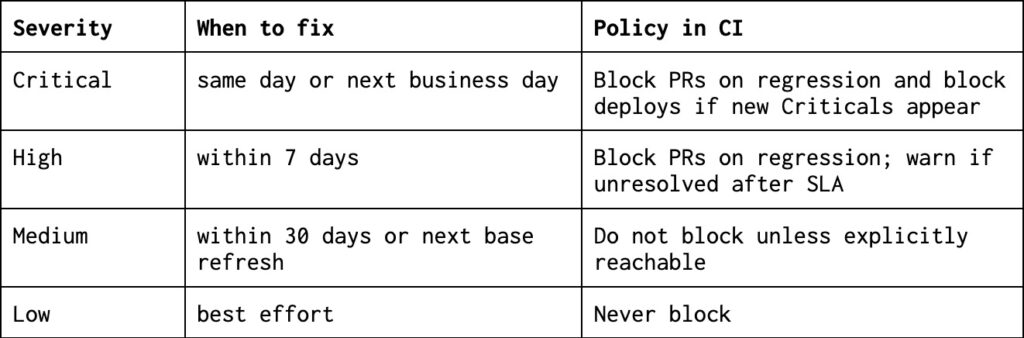
Push on two levers before touching the application code
- Refresh the base image suggested by the recommendations. This often clears the noisy majority in minutes.
- Switch to a slimmer base if your app allows it. debian:bookworm-slim or a minimal distroless image reduces attack surface, and your scanner reports will look cleaner because there is simply less there.
Use comparisons to stop bikeshedding
Make the conversation about direction rather than absolutes. If each PR is no worse than the baseline, you are winning.
Document exceptions as artifacts
When something is not reachable or is mitigated elsewhere, record it alongside the SBOM or in your tracking system. Invisible exceptions return like unwashed coffee mugs.
Common traps and how to step around them
The base image is doing most of the damage
If your report looks like a fireworks show, run recommendations. If it says “update base” and you ignore it, you are choosing to mop the floor while the tap stays open.
You still run everything as root
Even perfect CVE hygiene will not save you if the container has god powers. If you can, adopt a non‑root user and a slimmer runtime image. A typical multi‑stage pattern looks like this:
# Build stage
FROM golang:1.22 as builder
WORKDIR /src
COPY . .
RUN CGO_ENABLED=0 GOOS=linux go build -o /bin/app ./cmd/api
# Runtime stage
FROM gcr.io/distroless/static:nonroot
COPY --from=builder /bin/app /app
USER nonroot:nonroot
ENTRYPOINT ["/app"]Now your scanner report shrinks, and your container stops borrowing the keys to the building.
Your scanner finds Mediums you cannot fix today
Save your energy for issues with available fixes or for regressions. Mediums without fixes belong on a to‑do list, not a release gate.
The team treats the scanner as a chore
Keep the feedback quick and visible. Short PR notes, one SBOM per release, and a small monthly base refresh beat quarterly crusades.
Working with registries without drama
Local images work out of the box. For remote registries, enable analysis where you store images and authenticate normally through Docker. If you are using a private registry such as ECR or ACR, link it through the vendor’s integration or your registry settings, then keep using the same CLI commands. The aim is to avoid side channels and keep your workflow boring on purpose.
A lightweight checklist you can adopt this week
- Baseline today: run QuickView on your main images and keep the outputs as a reference.
- Gate on direction: use compare in PRs with exit-on: vulnerability limited to High and Critical.
- Refresh bases monthly: schedule a small chore day where you accept the recommended base image bumps and rebuild.
- Keep an SBOM: publish cyclonedx-json or SPDX for every release so audits are not a scavenger hunt.
- Write down exceptions: if you decide not to fix something, make the decision discoverable.
Frequently asked questions you will hear in standups
Can we silence CVEs that we do not ship to production
Yes. Focus on fixed Highs and Criticals, and gate only on regressions. Most other issues are housekeeping.
Will this slow our builds?
Not meaningfully when you keep output small and comparisons tight. It is cheaper than a hotfix sprint on Friday.
Do we need another dashboard?
You need visibility where developers live. Upload SARIF to Code Scanning, and you are done. The fewer tabs, the better.
Final nudge
Security that ships beats security that lectures. Start with a baseline, gate on direction, and keep a steady rhythm of base refreshes. In a couple of sprints, you will notice fewer alarms, fewer debates, and release notes that read like a grocery receipt instead of a hostage letter.
If your containers still show up with suspicious items in their pockets, at least now you can point to the pocket, the store it came from, and the cheaper replacement. That tiny bit of provenance is often the difference between a calm Tuesday and a war room with too much pizza.
If you remember nothing else, remember three habits. Run QuickView on your main images once a week. Let compare guard your pull requests. Accept the base refresh that Scout recommends each month. Everything else is seasoning.
Measure success by absence. Fewer “just-one-hotfix” pings at five on Friday. Fewer meetings where severity taxonomies are debated like baby names. More merges that feel like brushing your teeth, brief, boring, done.
Tools will not make you virtuous, but good routines will. Docker Scout shortens the routine and thins the excuses. Baseline today, set the gate, add a tiny chore to the calendar, and then go do something nicer with your afternoon.





