
Let us talk about healthcare data pipelines. Running high volume payer processing pipelines is a lot like hosting a mandatory potluck dinner for a group of deeply eccentric people with severe and conflicting dietary restrictions. Each payer behaves with maddening uniqueness. One payer bursts through the door, demanding an entire roasted pig, which they intend to consume in three minutes flat. This requires massive, short-lived computational horsepower. Another payer arrives with a single boiled pea and proceeds to chew it methodically for the next five hours, requiring a small but agonizingly persistent trickle of processing power.
On top of this culinary nightmare, there are strict rules of etiquette. You absolutely must digest the member data before you even look at the claims data. Eligibility files must be validated before anyone is allowed to touch the dessert tray of downstream jobs. The workload is not just heavy. It is incredibly uneven and delightfully complicated.
Buying folding chairs for a banquet
On paper, Amazon Web Services managed Auto Scaling Mechanisms should fix this problem. They are designed to look at a growing pile of work and automatically hire more help. But applying generic auto scaling to healthcare pipelines is like a restaurant manager seeing a line out the door and solving the problem by buying fifty identical plastic folding chairs.
The manager does not care that one guest needs a high chair and another requires a reinforced steel bench. Auto scaling reacts to the generic brute force of the system load. It cannot look at a specific payer and tailor the compute shape to fit their weird eating habits. It cannot enforce the strict social hierarchy of job priorities. It scales the infrastructure, but it completely fails to scale the intention.
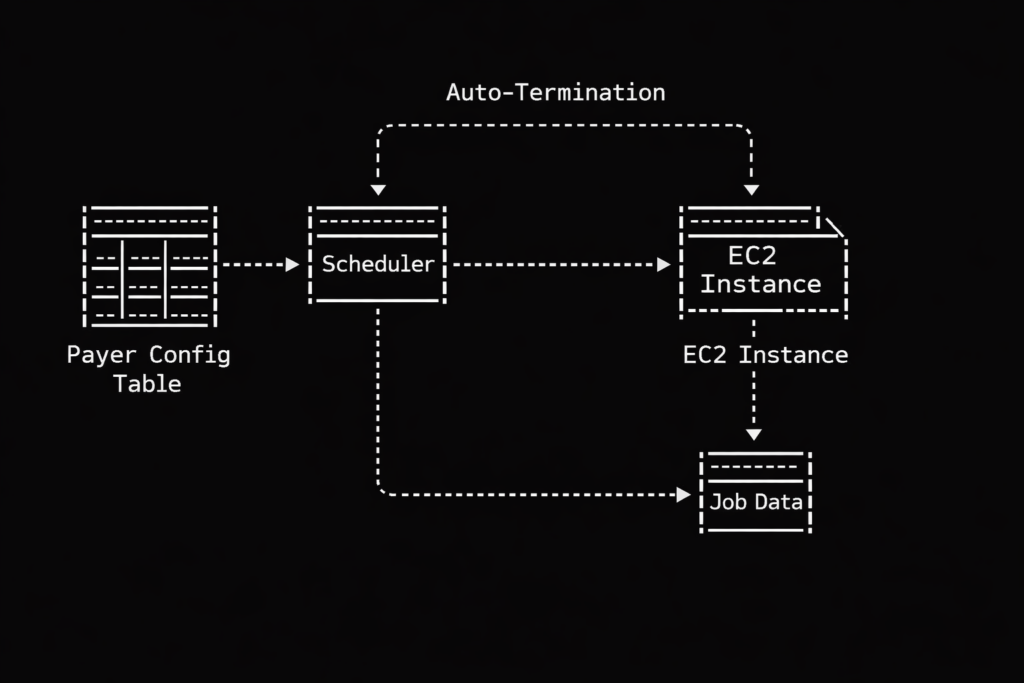
This is why we abandoned the generic approach and built our own dynamic EC2 provisioning system. Instead of maintaining a herd of generic servers waiting around for something to do, we create bespoke servers on demand based on a central configuration table.
The ruthless nightclub bouncer of job scheduling
Let us look at how this actually works regarding prioritization. Our system relies on that central configuration table to dictate order. Think of this table as the guest list at an obnoxiously exclusive nightclub. Our scheduler acts as the ruthless bouncer.
When jobs arrive at the queue, the bouncer checks the list. Member data? Right this way to the VIP lounge, sir. Claims data? Stand on the curb behind the velvet rope until the members are comfortably seated. Generic auto scaling has no native concept of this social hierarchy. It just sees a mob outside the club and opens the front doors wide. Our dynamic approach gives us perfect, tyrannical control over who gets processed first, ensuring our pipelines execute in a beautifully deterministic way. We spin up exactly the compute we specify, exactly when we want it.
Leaving your car running in the garage
Then there is the financial absurdity of warm pools. Standard auto scaling often relies on keeping a baseline of idle instances warm and ready, just in case a payer decides to drop a massive batch of files at two in the morning.
Keeping idle servers running is the technological equivalent of leaving your car engine idling in the closed garage all night just in case you get a sudden craving for a carton of milk at dawn. It is expensive, it is wasteful, and it makes you look a bit foolish when the AWS bill arrives.
Our dynamic system operates with a baseline of zero. We experience one hundred percent burst efficiency because we only pay for the exact compute we use, precisely when we use it. Cost savings happen naturally when you refuse to pay for things that are sitting around doing nothing.
A delightfully brutal server lifecycle
The operational model we ended up with is almost comically simple compared to traditional methods. A generic scaling group requires complex scaling policies, tricky cooldown periods, and endless tweaking of CloudWatch alarms. It is like managing a highly sensitive, moody teenager.
Our dynamic EC2 model is wonderfully ruthless. We create the instance and inject it with a single, highly specific purpose via a startup script. The instance wakes up, processes the healthcare data with absolute precision, and then politely self destructs so it stops billing us. They are the mayflies of the cloud computing world. They live just long enough to do their job, and then they vanish. There are no orphaned instances wandering the cloud.
This dynamic provisioning model has fundamentally altered how we digest payer workloads. We have somehow achieved a weird but perfect holy grail of cloud architecture. We get the granular flexibility of serverless functions, the raw, unadulterated horsepower of dedicated EC2 instances, and the stingy cost efficiency of a pure event-driven design.
If your processing jobs vary wildly from payer to payer, and if you care deeply about enforcing priorities without burning money on idle metal, building a disposable compute army might be exactly what your architecture is missing. We said goodbye to our idle servers, and honestly, we do not miss them at all.
