When you think about Kubernetes, you might picture a vast orchestra with dozens of instruments, each critical for delivering a grand performance. It’s perfect when you have to manage huge, complex applications. But let’s be honest, sometimes all you need is a simple tune played by a skilled guitarist, something agile and efficient. That’s precisely what K3s offers: the elegance of Kubernetes without overwhelming complexity.
What exactly is K3s?
K3s is essentially Kubernetes stripped down to its essentials, carefully crafted by Rancher Labs to address a common frustration: complexity. Think of it as a precisely engineered solution designed to thrive in environments where resources and computing power are limited. Picture scenarios such as small-scale IoT deployments, edge computing setups, or even weekend Raspberry Pi experiments. Unlike traditional Kubernetes, which can feel cumbersome on such modest devices, K3s trims down the system by removing heavy legacy APIs, unnecessary add-ons, and less frequently used features. Its name offers a playful yet clever clue: the original Kubernetes is abbreviated as K8s, representing the eight letters between ‘K’ and ‘s.’ With fewer components, this gracefully simplifies to K3s, keeping the core essentials intact without losing functionality or ease of use.
Why choose K3s?
If your projects aren’t running massive applications, deploying standard Kubernetes can feel excessive, like using a large truck to carry a single bag of groceries. Here’s where K3s shines:
Edge Computing: Perfect for lightweight, low-resource environments where efficiency and speed matter more than extensive features.
IoT and Small Devices: Ideal for setting up on compact hardware like Raspberry Pi, delivering functionality without consuming excessive resources.
Development and Testing: Quickly spin up lightweight clusters for testing without bogging down your system.
Key Differences Between Kubernetes and K3s
When comparing Kubernetes and K3s, several fundamental differences truly set K3s apart, making it ideal for smaller-scale projects or resource-constrained environments:
Installation Time: Kubernetes installations often require multiple steps, complex dependencies, and extensive configurations. K3s simplifies this into a quick, single-step installation.
Resource Usage: Standard Kubernetes can be resource-intensive, demanding substantial CPU and memory even when idle. K3s drastically reduces resource consumption, efficiently running on modest hardware.
Binary Size: Kubernetes needs multiple binaries and services, contributing significantly to its size and complexity. K3s consolidates everything into a single, compact binary, simplifying management and updates.
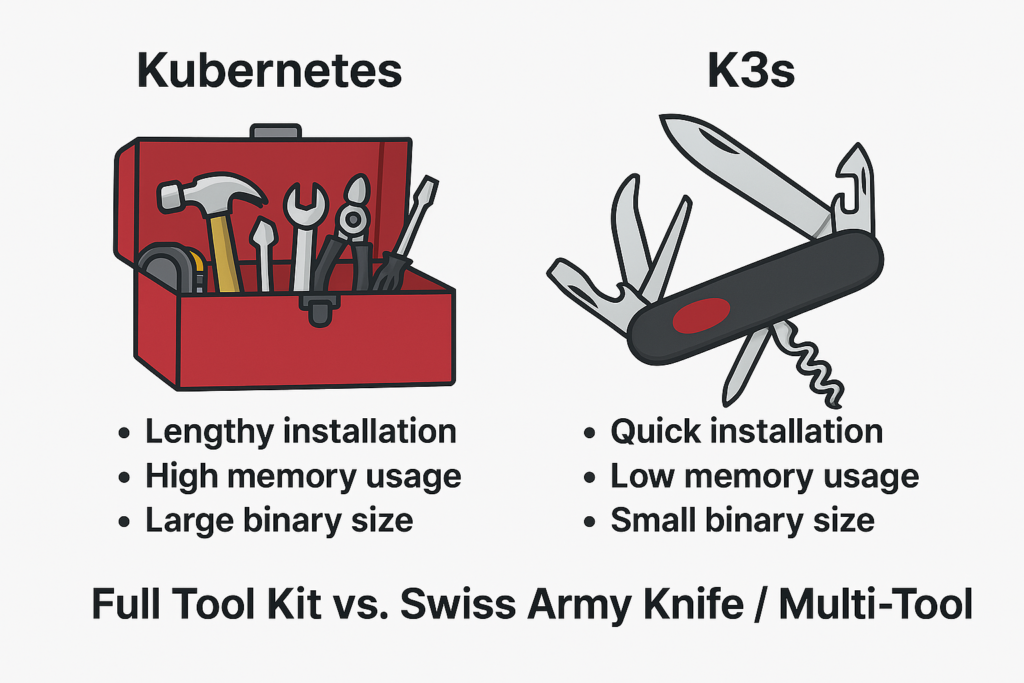
Here’s a visual analogy to help solidify this concept:
This illustration encapsulates why K3s might be the perfect fit for your lightweight needs.
K3s vs Kubernetes
K3s elegantly cuts through Kubernetes’s complexity by thoughtfully removing legacy APIs, rarely-used functionalities, and heavy add-ons typically burdening smaller environments without adding real value. This meticulous pruning ensures every included feature has a practical purpose, dramatically improving performance on resource-limited hardware. Additionally, K3s’ packaging into a single binary greatly simplifies installation and ongoing management.
Imagine assembling a model airplane. Standard Kubernetes hands you a comprehensive yet daunting kit with hundreds of small, intricate parts, instructions filled with technical jargon, and tools you might never use again. K3s, however, gives you precisely the parts required, neatly organized and clearly labeled, with instructions so straightforward that the process becomes not only manageable but enjoyable. This thoughtful simplification transforms a potentially frustrating task into an approachable and delightful experience.
Getting K3s up and running
One of K3s’ greatest appeals is its effortless setup. Instead of wrestling with numerous installation files, you only need one simple command:
curl -sfL https://get.k3s.io | sh -
That’s it! Your cluster is ready. Verify that everything is running smoothly:
kubectl get nodes
If your node appears listed, you’re off to the races!
Adding Additional Nodes
When one node isn’t sufficient, adding extra nodes is straightforward. Use a join command to connect new nodes to your existing cluster. Here, the variable AGENT_IP represents the IP address of the machine you’re adding as a node. Clearly specifying this tells your K3s cluster exactly where to connect the new node. Ensure you specify the server’s IP and match the K3s version across nodes for seamless integration:
Congratulations! You’ve successfully deployed your first lightweight app on K3s.
Fun and practical uses for your K3s cluster
K3s isn’t just practical it’s also enjoyable. Here are some quick projects to build your confidence:
Simple Web Server: Host your static website using NGINX or Apache, easy and ideal for beginners.
Personal Wiki: Deploy Wiki.js to take notes or document projects, quickly grasping persistent storage essentials.
Development Environment: Create a small-scale development environment by combining a backend service with MySQL, mastering multi-container management.
These activities provide practical skills while leveraging your new K3s setup.
Embracing the joy of simplicity
K3s beautifully demonstrates that true power can reside in simplicity. It captures Kubernetes’s essential spirit without overwhelming you with unnecessary complexity. Instead of dealing with an extensive toolkit, K3s offers just the right components, intuitive, clear, and thoughtfully chosen to keep you creative and productive. Whether you’re tinkering at home, deploying services on minimal hardware, or exploring container orchestration basics, K3s ensures you spend more time building and less time troubleshooting. This is simplicity at its finest, a gentle reminder that great technology doesn’t need to be intimidating; it just needs to be thoughtfully designed and easy to enjoy.
Let’s chat about something interesting in the Kubernetes world called KCP. What is it? Well, KCP stands for Kubernetes-like Control Plane. The neat trick here is that it lets you use the familiar Kubernetes way of managing things (the API) without needing a whole, traditional Kubernetes cluster humming away. We’ll unpack what KCP is, see how it stacks up against regular Kubernetes, and glance at some other tools doing similar jobs.
So what is KCP then
At its heart, KCP is an open-source project giving you a control center, or ‘control plane’, that speaks the Kubernetes language. Its big idea is to help manage applications that might be spread across different clusters or environments.
Now, think about standard Kubernetes. It usually does two jobs: it’s the ‘brain’ figuring out what needs to run where (that’s the control plane), and it also manages the ‘muscles’, the actual computers (nodes) running your applications (that’s the data plane). KCP is different because it focuses only on being the brain. It doesn’t directly manage the worker nodes or pods doing the heavy lifting.
Why is this separation useful? It lets people building platforms or Software-as-a-Service (SaaS) products use the Kubernetes tools and methods they already like, but without the extra work and cost of running all the underlying cluster infrastructure themselves.
Think of it like this: KCP is kind of like a super-smart universal remote control. One remote can manage your TV, your sound system, maybe even your streaming box, right? KCP is similar, it can send commands (API calls) to lots of different Kubernetes setups or other services, telling them what to do without being physically part of any single one. It orchestrates things from a central point.
A couple of key KCP ideas
Workspaces: KCP introduces something called ‘workspaces’. You can think of these as separate, isolated booths within the main KCP control center. Each workspace acts almost like its own independent Kubernetes cluster. This is fantastic for letting different teams or projects work side by side without bumping into each other or messing up each other’s configurations. It’s like giving everyone their own sandbox in the same playground.
Speaks Kubernetes: Because KCP uses the standard Kubernetes APIs, you can talk to it using the tools you probably already use, like kubectl. This means developers don’t have to learn a whole new set of commands. They can manage their applications across various places using the same skills and configurations.
How KCP is not quite Kubernetes
While KCP borrows the language of Kubernetes, it functions quite differently.
Just The Control Part: As we mentioned, Kubernetes is usually both the manager and the workforce rolled into one. It orchestrates containers and runs them on nodes. KCP steps back and says, “I’ll just be the manager.” It handles the orchestration logic but leaves the actual running of applications to other places.
Built For Sharing: KCP was designed from the ground up to handle lots of different users or teams safely (that’s multi-tenancy). You can carve out many ‘logical’ clusters inside a single KCP instance. Each team gets their isolated space without needing completely separate, resource-hungry Kubernetes clusters for everyone.
Doesn’t Care About The Hardware: Regular Kubernetes needs a bunch of servers (physical or virtual nodes) to operate. KCP cuts the cord between the control brain and the underlying hardware. It can manage resources across different clouds or data centers without being tied to specific machines.
Imagine a big company with teams scattered everywhere, each needing their own Kubernetes environment. The traditional approach might involve spinning up dozens of individual clusters, complex, costly, and hard to manage consistently. KCP offers a different path: create multiple logical workspaces within one shared KCP control plane. It simplifies management and cuts down on wasted resources.
What are the other options
KCP is cool, but it’s not the only tool for exploring this space. Here are a few others:
Kubernetes Federation (Kubefed): Kubefed is also about managing multiple clusters from one spot, helping you spread applications across them. The main difference is that Kubefed generally assumes you already have multiple full Kubernetes clusters running, and it works to keep resources synced between them.
OpenShift: This is Red Hat’s big, feature-packed Kubernetes platform aimed at enterprises. It bundles in developer tools, build pipelines, and more. It has a powerful control plane, but it’s usually tightly integrated with its own specific data plane and infrastructure, unlike KCP’s more detached approach.
Crossplane: Crossplane takes Kubernetes concepts and stretches them to manage more than just containers. It lets you use Kubernetes-style APIs to control external resources like cloud databases, storage buckets, or virtual networks. If your goal is to manage both your apps and your cloud infrastructure using Kubernetes patterns, Crossplane is worth a look.
So, if you need to manage cloud services alongside your apps via Kubernetes APIs, Crossplane might be your tool. But if you’re after a streamlined, scalable control plane primarily for orchestrating applications across many teams or environments without directly managing the worker nodes, KCP presents a compelling case.
So what’s the big picture?
We’ve taken a little journey through KCP, exploring what makes it tick. The clever idea at its core is splitting things up, separating the Kubernetes ‘brain’ (the control plane that makes decisions) from the ‘muscles’ (the data plane where applications actually run). It’s like having that universal remote that knows how to talk to everything without being the TV or the soundbar itself.
Why does this matter? Well, pulling apart these pieces brings some real advantages to the table. It makes KCP naturally suited for situations where you have lots of different teams or applications needing their own space, without the cost and complexity of firing up separate, full-blown Kubernetes clusters for everyone. That multi-tenancy aspect is a big deal. Plus, detaching the control plane from the underlying hardware offers a lot of flexibility; you’re not tied to managing specific nodes just to get that Kubernetes API goodness.
For people building internal platforms, creating SaaS offerings, or generally trying to wrangle application management across diverse environments, KCP presents a genuinely different angle. It lets you keep using the Kubernetes patterns and tools many teams are comfortable with, but potentially in a much lighter, more scalable, and efficient way, especially when you don’t need or want to manage the full cluster stack directly.
Of course, KCP is still a relatively new player, and the landscape of cloud-native tools is always shifting. But it offers a compelling vision for how control planes might evolve, focusing purely on orchestration and API management at scale. It’s a fascinating example of rethinking familiar patterns to solve modern challenges and certainly a project worth keeping an eye on as it develops.
Cloud-native applications aren’t just a passing trend, they’re becoming the heart of how modern businesses deliver digital services. As organizations increasingly adopt cloud solutions, they’ve realized something quite fascinating. DevOps isn’t just nice to have; it has become essential.
Let’s explore why DevOps has become crucial for cloud-native applications and how it genuinely improves their lifecycle.
Streamlining releases with Continuous Integration and Continuous Deployment
Cloud-native apps are built differently. Instead of giant, complex systems, they consist of small, focused microservices, each responsible for a single job. These can be updated independently, allowing fast, precise changes.
Updating hundreds of small services manually would be incredibly challenging, like organizing a library without any shelves. DevOps offers an elegant solution through Continuous Integration (CI) and Continuous Deployment (CD). Tools such as Jenkins, GitLab CI/CD, GitHub Actions, and AWS CodePipeline help automate these processes. Every time someone makes a change, it gets automatically tested and safely pushed into production if everything checks out.
This automation significantly reduces errors, accelerates fixes, and lowers stress levels. It feels as smooth as a well-oiled machine, efficiently delivering features from developers to users.
Avoiding mistakes with intelligent automation
Manual tasks aren’t just tedious, they’re expensive, slow, and error-prone. With cloud-native applications constantly changing and scaling, manual processes quickly become unmanageable.
DevOps solves this through smart automation. Tools like Terraform, Ansible, Puppet, and Kubernetes ensure consistency and correctness in every step, from provisioning servers to deploying applications. Imagine never having to worry about misconfigured settings or mismatched versions again.
Need more resources? Just use AWS CloudFormation or Azure Resource Manager, and additional infrastructure is instantly available. Automation frees up your time, letting your team focus on innovation and creativity.
Enhancing visibility through continuous monitoring
When your application consists of many interconnected services in the cloud, clear visibility becomes vital. DevOps incorporates continuous monitoring at every stage, ensuring no issue remains unnoticed.
With tools like Prometheus, Grafana, Datadog, or Splunk, teams swiftly spot performance issues, errors, or security threats. It’s not just reactive troubleshooting; it’s proactive improvement, ensuring your application stays healthy, reliable, and scalable, even under intense complexity.
Faster and more reliable releases through Automated Testing
Testing often bottlenecks software delivery, especially for fast-moving cloud-native apps. There’s simply no time for slow testing cycles.
That’s why DevOps relies on automated testing frameworks and tools such as Selenium, JUnit, Jest, or Cypress. Each microservice and the overall application are tested automatically whenever changes occur. This accelerates release cycles and dramatically improves quality. Issues get caught early, long before they impact users, letting you confidently deploy new versions.
Empowering teams with effective collaboration
Cloud-native applications often involve multiple teams working simultaneously. Without strong collaboration, things fall apart quickly.
DevOps fosters continuous collaboration by breaking down barriers between developers, operations, and QA teams. Platforms like Slack, Jira, Confluence, and Microsoft Teams provide shared resources, clear communication, and transparent processes. Collaboration isn’t optional, it’s built into every aspect of the workflow, making complex projects more manageable and innovation faster.
Thriving with DevOps
DevOps isn’t just beneficial, it’s vital for cloud-native applications. By automating tasks, accelerating releases, proactively addressing issues, and boosting team collaboration, DevOps fundamentally changes how software is created and maintained. It transforms intimidating complexity into simplicity, enabling you to manage numerous microservices efficiently and calmly. More than that, DevOps enhances team satisfaction by eliminating tedious manual tasks, allowing everyone to focus on creativity and meaningful innovation.
Ultimately, mastering DevOps isn’t only about keeping up, it’s about empowering your team to create smarter, respond faster, and deliver better software. In today’s rapidly evolving cloud-native field, embracing DevOps fully might just be the most rewarding decision you can make.
When you first start using Kubernetes, Pods might seem straightforward. Initially, they look like simple containers grouped, right? But hidden beneath this simplicity are powerful techniques that can elevate your Kubernetes deployments from merely functional to exceptionally robust, efficient, and secure. Let’s explore these advanced Kubernetes Pod concepts and empower DevOps engineers, Site Reliability Engineers (SREs), and curious developers to build better, stronger, and smarter systems.
Multi-Container Pods, a Closer Look
Beginners typically deploy Pods containing just one container. But Kubernetes offers more: you can bundle several containers within a single Pod, letting them efficiently share resources like network and storage.
Sidecar pattern in Action
Imagine giving your application a helpful partner, that’s what a sidecar container does. It’s like having a dependable assistant who quietly manages important details behind the scenes, allowing you to focus on your primary tasks without distraction. A sidecar container handles routine but essential responsibilities such as logging, monitoring, or data synchronization, tasks your main application shouldn’t need to worry about directly. For instance, while your main app engages users, responds to requests, and processes transactions, the sidecar can quietly collect logs and forward them efficiently to a logging system. This clever separation of concerns simplifies development and enhances reliability by isolating additional functionality neatly alongside your main application.
Adapters are essentially translators, they take your application’s outputs and reshape them into forms that other external systems can easily understand. Think of them as diplomats who speak the language of multiple systems, bridging communication gaps effortlessly. Ambassadors, on the other hand, serve as intermediaries or dedicated representatives, handling external interactions on behalf of your main container. Imagine your application needing frequent access to an external API; the ambassador container could manage local caching and simplify interactions, reducing latency and speeding up response times dramatically. Both adapters and ambassadors cleverly streamline integration and improve overall system efficiency by clearly defining responsibilities and interactions.
Init containers, setting the stage
Before your Pod kicks into gear and starts its primary job, there’s usually a bit of groundwork to lay first. Just as you might check your toolbox and gather your materials before starting a project, init containers take care of essential setup tasks for your Pods. These handy containers run before the main application container and handle critical chores such as verifying database connections, downloading necessary resources, setting up configuration files, or tweaking file permissions to ensure everything is in the right state. By using init containers, you’re ensuring that when your application finally says, “Ready to go!”, it is ready, avoiding potential hiccups and smoothing out your application’s startup process.
Strengthening Pod stability with disruption budgets
Pods aren’t permanent; they can be disrupted by routine maintenance or unexpected failures. Pod Disruption Budgets (PDBs) keep services running smoothly by ensuring a minimum number of Pods remain active, even during disruptions.
This setup ensures Kubernetes maintains at least two active Pods at all times.
Scheduling mastery with Pod affinity and anti-affinity
Affinity and anti-affinity rules help Kubernetes make smart decisions about Pod placement, almost as if the Pods themselves have preferences about where they want to live. Think of affinity rules as Pods that prefer to hang out together because they benefit from proximity, like friends working better in the same office. For instance, clustering database Pods together helps reduce latency, ensuring faster communication. On the other hand, anti-affinity rules act more like Pods that prefer their own space, spreading frontend Pods across multiple nodes to ensure that if one node experiences trouble, others continue operating smoothly. By mastering these strategies, you enable Kubernetes to optimize your application’s performance and resilience in a thoughtful, almost intuitive manner.
Affinity example (Grouping Together):
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: role
operator: In
values:
- database
topologyKey: "kubernetes.io/hostname"
Anti-Affinity example (Spreading Apart):
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: role
operator: In
values:
- webserver
topologyKey: "kubernetes.io/hostname"
Pod health checks. Readiness, Liveness, and Startup Probes
Kubernetes regularly checks the health of your Pods through:
Readiness Probes: Confirm your Pod is ready to handle traffic.
Liveness Probes: Continuously check Pod responsiveness and restart if necessary.
Startup Probes: Give Pods ample startup time before running other probes.
Pods need resources like CPU and memory, much like how you need food and energy to stay productive throughout the day. But just as you shouldn’t overeat or exhaust yourself, Pods should also be careful with resource usage. Kubernetes provides an elegant solution to this challenge by letting you politely request the resources your Pod requires and firmly setting limits to prevent excessive consumption. This thoughtful management ensures every Pod gets its fair share, maintaining harmony in the shared environment, and helping prevent resource-starvation issues that could slow down or disrupt the entire system.
Precise Pod scheduling with taints and tolerations
In Kubernetes, nodes sometimes have specific conditions or labels called “taints.” Think of these taints as signs on the doors of rooms saying, “Only enter if you need what’s inside.” Pods respond to these taints by using something called “tolerations,” essentially a way for Pods to say, “Yes, I recognize the conditions of this node, and I’m fine with them.” This clever mechanism ensures that Pods are selectively scheduled onto nodes best suited for their specific needs, optimizing resources and performance in your Kubernetes environment.
Ephemeral storage is like scribbling a quick note on a chalkboard, useful for temporary reminders or short-term calculations, but easily erased. When Pods restart, everything stored in ephemeral storage vanishes, making it ideal for temporary data that you won’t miss. Persistent storage, however, is akin to carefully writing down important notes in your notebook, where they’re preserved safely even after you close it. This type of storage maintains its contents across Pod restarts, making it perfect for storing critical, long-term data that your application depends on for continued operation.
Horizontal scaling is like having extra hands on deck precisely when you need them. If your application suddenly faces increased traffic, imagine a store suddenly swarming with customers, you quickly bring in additional help by spinning up more Pods. Conversely, when things slow down, you gracefully scale back to conserve resources. Vertical scaling, however, is more about fine-tuning the capabilities of each Pod individually. Think of it as providing a worker with precisely the right tools and workspace they need to perform their job efficiently. Kubernetes dynamically adjusts the resources allocated to each Pod, ensuring they always have the perfect amount of CPU and memory for their workload, no more and no less. These strategies together keep your applications agile, responsive, and resource-efficient.
Network policies act like traffic controllers for your Pods, deciding who talks to whom and ensuring unwanted visitors stay away. Imagine hosting an exclusive gathering, only guests are allowed in. Similarly, network policies permit Pods to communicate strictly according to defined rules, enhancing security significantly. For instance, you might allow only your frontend Pods to interact directly with backend Pods, preventing potential intruders from sneaking into sensitive areas. This strategic control keeps your application’s internal communications safe, orderly, and efficient.
Now imagine you’re standing in a vast workshop, tools scattered around you. At first glance, a Pod seems like a simple wooden box, unassuming, almost ordinary. But open it up, and inside you’ll find gears, springs, and levers arranged with precision. Each component has a purpose, and when you learn to tweak them just right, that humble box transforms into something extraordinary: a clock that keeps perfect time, a music box that hums symphonies, or even a tiny engine that powers a locomotive.
That’s the magic of mastering Kubernetes Pods. You’re not just deploying containers; you’re orchestrating tiny ecosystems. Think of the sidecar pattern as adding a loyal assistant who whispers, “Don’t worry about the logs, I’ll handle them. You focus on the code.” Or picture affinity rules as matchmakers, nudging Pods to cluster together like old friends at a dinner party, while anti-affinity rules act likewise parents, saying, “Spread out, kids, no crowding the kitchen!”
And what about those init containers? They’re the stagehands of your Pod’s theater. Before the spotlight hits your main app, these unsung heroes sweep the floor, adjust the curtains, and test the microphones. No fanfare, just quiet preparation. Without them, the show might start with a screeching feedback loop or a missing prop.
But here’s the real thrill: Kubernetes isn’t a rigid rulebook. It’s a playground. When you define a Pod Disruption Budget, you’re not just setting guardrails, you’re teaching your cluster to say, “I’ll bend, but I won’t break.” When you tweak resource limits, you’re not rationing CPU and memory; you’re teaching your apps to dance gracefully, even when the music speeds up.
And let’s not forget security. With Network Policies, you’re not just building walls, you’re designing secret handshakes. “Psst, frontend, you can talk to the backend, but no one else gets the password.” It’s like hosting a masquerade ball where every guest is both mysterious and meticulously vetted.
So, what’s the takeaway? Kubernetes Pods aren’t just YAML files or abstract concepts. They’re living, breathing collaborators. The more you experiment, tinkering with probes, laughing at the quirks of taints and tolerations, or marveling at how ephemeral storage vanishes like chalk drawings in the rain, the more you’ll see patterns emerge. Patterns that whisper, “This is how systems thrive.”
Will there be missteps? Of course! Maybe a misconfigured probe or a Pod that clings to a node like a stubborn barnacle. But that’s the joy of it. Every hiccup is a puzzle and every solution? A tiny epiphany. So go ahead, grab those Pods, twist them, prod them, and watch as your deployments evolve from “it works” to “it sings.” The journey isn’t about reaching perfection. It’s about discovering how much aliveness you can infuse into those lines of YAML. And trust me, the orchestra you’ll conduct? It’s worth every note.
Containers have transformed how we build, deploy, and run software. We package our apps neatly into them, toss them onto Kubernetes, and sit back as things smoothly fall into place. But hidden beneath this simplicity is a critical component quietly doing all the heavy lifting, the container runtime. Let’s explain and clearly understand what this container runtime is, why it matters, and how it helps everything run seamlessly.
What exactly is a Container Runtime?
A container runtime is simply the software that takes your packaged application and makes it run. Think of it like the engine under the hood of your car; you rarely think about it, but without it, you’re not going anywhere. It manages tasks like starting containers, isolating them from each other, managing system resources such as CPU and memory, and handling important resources like storage and network connections. Thanks to runtimes, containers remain lightweight, portable, and predictable, regardless of where you run them.
Why should you care about Container Runtimes?
Container runtimes simplify what could otherwise become a messy job of managing isolated processes. Kubernetes heavily relies on these runtimes to guarantee the consistent behavior of applications every single time they’re deployed. Without runtimes, managing containers would be chaotic, like cooking without pots and pans, you’d end up with scattered ingredients everywhere, and things would quickly get messy.
Getting to know the popular Container Runtimes
Let’s explore some popular container runtimes that you’re likely to encounter:
Docker
Docker was the original popular runtime. It played a key role in popularizing containers, making them accessible to developers and enterprises alike. Docker provides an easy-to-use platform that allows applications to be packaged with all their dependencies into lightweight, portable containers.
One of Docker’s strengths is its extensive ecosystem, including Docker Hub, which offers a vast library of pre-built images. This makes it easy to find and deploy applications quickly. Additionally, Docker’s CLI and tooling simplify the development workflow, making container management straightforward even for those new to the technology.
However, as Kubernetes evolved, it moved away from relying directly on Docker. This was mainly because Docker was designed as a full-fledged container management platform rather than a lightweight runtime. Kubernetes required something leaner that focused purely on running containers efficiently without unnecessary overhead. While Docker still works well, most Kubernetes clusters now use containerd or CRI-O as their primary runtime for better performance and integration.
containerd
Containerd emerged from Docker as a lightweight, efficient, and highly optimized runtime that focuses solely on running containers. If Docker is like a full-service restaurant—handling everything from taking orders to cooking and serving, then containerd is just the kitchen. It does the cooking, and it does it well, but it leaves the extra fluff to other tools.
What makes containerd special? First, it’s built for speed and efficiency. It strips away the unnecessary components that Docker carries, focusing purely on running containers without the added baggage of a full container management suite. This means fewer moving parts, less resource consumption, and better performance in large-scale Kubernetes environments.
Containerd is now a graduated project under the Cloud Native Computing Foundation (CNCF), proving its reliability and widespread adoption. It’s the default runtime for many managed Kubernetes services, including Amazon EKS, Google GKE, and Microsoft AKS, largely because of its deep integration with Kubernetes through the Container Runtime Interface (CRI). This allows Kubernetes to communicate with containerd natively, eliminating extra layers and complexity.
Despite its strengths, containerd lacks some of the convenience features that Docker offers, like a built-in CLI for managing images and containers. Users often rely on tools like ctr or crictl to interact with it directly. But in a Kubernetes world, this isn’t a big deal, Kubernetes itself takes care of most of the higher-level container management.
With its low overhead, strong Kubernetes integration, and widespread industry support, containerd has become the go-to runtime for modern containerized workloads. If you’re running Kubernetes today, chances are containerd is quietly doing the heavy lifting in the background, ensuring your applications start up reliably and perform efficiently.
CRI-O
CRI-O is designed specifically to meet Kubernetes standards. It perfectly matches Kubernetes’ Container Runtime Interface (CRI) and focuses solely on running containers. If Kubernetes were a high-speed train, CRI-O would be the perfectly engineered rail system built just for it, streamlined, efficient, and without unnecessary distractions.
One of CRI-O’s biggest strengths is its tight integration with Kubernetes. It was built from the ground up to support Kubernetes workloads, avoiding the extra layers and overhead that come with general-purpose container platforms. Unlike Docker or even containerd, which have broader use cases, CRI-O is laser-focused on running Kubernetes workloads efficiently, with minimal resource consumption and a smaller attack surface.
Security is another area where CRI-O shines. Since it only implements the features Kubernetes needs, it reduces the risk of security vulnerabilities that might exist in larger, more feature-rich runtimes. CRI-O is also fully OCI-compliant, meaning it supports Open Container Initiative images and integrates well with other OCI tools.
However, CRI-O isn’t without its downsides. Because it’s so specialized, it lacks some of the broader ecosystem support and tooling that containerd and Docker enjoy. Its adoption is growing, but it’s not as widely used outside of Kubernetes environments, meaning you may not find as much community support compared to the more established runtimes. Despite these trade-offs, CRI-O remains a great choice for teams that want a lightweight, Kubernetes-native runtime that prioritizes efficiency, security, and streamlined performance.
Kata Containers
Kata Containers offers stronger isolation by running containers within lightweight virtual machines. It’s perfect for highly sensitive workloads, providing a security level closer to traditional virtual machines. But this added security comes at a cost, it typically uses more resources and can be slower than other runtimes. Consider Kata Containers as placing your app inside a secure vault, ideal when security is your top priority.
gVisor
Developed by Google, gVisor offers enhanced security by running containers within a user-space kernel. This approach provides isolation closer to virtual machines without requiring traditional virtualization. It’s excellent for workloads needing stronger isolation than standard containers but less overhead than full VMs. However, gVisor can introduce a noticeable performance penalty, especially for resource-intensive applications, because system calls must pass through its user-space kernel.
Kubernetes and the Container Runtime Interface
Kubernetes interacts with container runtimes using something called the Container Runtime Interface (CRI). Think of CRI as a universal translator, allowing Kubernetes to clearly communicate with any runtime. Kubernetes sends instructions, like launching or stopping containers, through CRI. This simple interface lets Kubernetes remain flexible, easily switching runtimes based on your needs without fuss.
Choosing the right Runtime for your needs
Selecting the best runtime depends on your priorities:
Efficiency – Does it maximize system performance?
Complexity: Does it avoid adding unnecessary complications?
Security: Does it provide the isolation level your applications demand?
If security is crucial, like handling sensitive financial or medical data, you might prefer runtimes like Kata Containers or gVisor, specifically designed for stronger isolation.
Final thoughts
Container runtimes might not grab headlines, but they’re crucial. They quietly handle the heavy lifting, making sure your containers run smoothly, securely, and efficiently. Even though they’re easy to overlook, runtimes are like the backstage crew of a theater production, diligently working behind the curtains. Without them, even the simplest container deployment would quickly turn into chaos, causing applications to crash, misbehave, or even compromise security. Every time you launch an application effortlessly onto Kubernetes, it’s because the container runtime is silently solving complex problems for you. So, the next time your containers spin up flawlessly, take a moment to appreciate these hidden champions, they might not get applause, but they truly deserve it.
I was thinking the other day about these Kubernetes pods, and how they’re like little spaceships floating around in the cluster. But what happens if one of those spaceships suddenly vanishes? Poof! Gone! That’s a real problem. So I started wondering, how can we ensure our pods are always there, ready to do their job, even if things go wrong? It’s like trying to keep a juggling act going while someone’s moving the floor around you…
Let me tell you about this tool called Karpenter. It’s like a super-efficient hotel manager for our Kubernetes worker nodes, always trying to arrange the “guests” (our applications) most cost-effectively. Sometimes, this means moving guests from one room to another to save on operating costs. In Kubernetes terminology, we call this “consolidation.”
The dancing pods challenge
Here’s the thing: We have this wonderful hotel manager (Karpenter) who’s doing a fantastic job, keeping costs down by constantly optimizing room assignments. But what about our guests (the applications)? They might get a bit dizzy with all this moving around, and sometimes, their important work gets disrupted.
So, the question is: How do we keep our applications running smoothly while still allowing Karpenter to do its magic? It’s like trying to keep a circus performance going while the stage crew rearranges the set in the middle of the act.
Understanding the moving parts
Before we explore the solutions, let’s take a peek behind the scenes and see what happens when Karpenter decides to relocate our applications. It’s quite a fascinating process:
First, Karpenter puts up a “Do Not Disturb” sign (technically called a taint) on the node it wants to clear. Then, it finds new accommodations for all the applications. Finally, it carefully moves each application to its new location.
Think of it as a well-choreographed dance where each step must be perfectly timed to avoid any missteps.
The art of high availability
Now, for the exciting part, we have some clever tricks up our sleeves to ensure our applications keep running smoothly:
The buddy system: The first rule of high availability is simple: never go it alone! Instead of running a single instance of your application, run at least two. It’s like having a backup singer, if one voice falters, the show goes on. In Kubernetes, we do this by setting replicas: 2 in our deployment configuration.
Strategic placement: Here’s a neat trick: we can tell Kubernetes to spread our application copies across different physical machines. It’s like not putting all your eggs in one basket. We use something called “Pod Topology Spread Constraints” for this. Here’s how it looks in practice:
Setting boundaries: Remember when your parents set rules about how many cookies you could eat? We do something similar in Kubernetes with PodDisruptionBudgets (PDB). We tell Kubernetes, “Hey, you must always keep at least 50% of my application instances running.” This prevents our hotel manager from getting too enthusiastic about rearranging things.
The “Do Not Disturb” sign: For those special cases where we absolutely don’t want an application to be moved, we can put up a permanent “Do Not Disturb” sign using the karpenter.sh/do-not-disrupt: “true” annotation. It’s like having a VIP guest who gets to keep their room no matter what.
The complete picture
The beauty of this system lies in how all the pieces work together. Think of it as a safety net with multiple layers:
Multiple instances ensure basic redundancy.
Strategic placement keeps instances separated.
PodDisruptionBudgets prevent too many moves at once.
And when necessary, we can completely prevent disruption.
A real example
Let me paint you a picture. Imagine you’re running a critical web service. Here’s how you might set it up:
With these patterns in place, our applications become incredibly resilient. They can handle node failures, scale smoothly, and even survive Karpenter’s optimization efforts without any downtime. It’s like having a self-healing system that keeps your services running no matter what happens behind the scenes.
High availability isn’t just about having multiple copies of our application, it’s about thoughtfully designing how those copies are managed and maintained. By understanding and implementing these patterns, we are not just running applications in Kubernetes; we are crafting reliable, resilient services that can weather any storm.
The next time you deploy an application to Kubernetes, think about these patterns. They might just save you from that dreaded 3 AM wake-up call about your service being down!
Choosing the right tool for continuous deployments is a big decision. It’s like picking the right vehicle for a road trip. Do you go for the thrill of a sports car or the reliability of a sturdy truck? In our world, the “cargo” is your application, and we want to ensure it reaches its destination smoothly and efficiently.
Two popular tools for this task are Helm and Kustomize. Both help you manage and deploy applications on Kubernetes, but they take different approaches. Let’s dive in, explore how they work, and help you decide which one might be your ideal travel buddy.
What is Helm?
Imagine Helm as a Kubernetes package manager, similar to apt or yum if you’ve worked with Linux before. It bundles all your application’s Kubernetes resources (like deployments, services, etc.) into a neat Helm chart package. This makes installing, upgrading, and even rolling back your application straightforward.
Think of a Helm chart as a blueprint for your application’s desired state in Kubernetes. Instead of manually configuring each element, you have a pre-built plan that tells Kubernetes exactly how to construct your environment. Helm provides a command-line tool, helm, to create these charts. You can start with a basic template and customize it to suit your needs, like a pre-fabricated house that you can modify to match your style. Here’s what a typical Helm chart looks like:
mychart/
Chart.yaml # Describes the chart
templates/ # Contains template files
deployment.yaml # Template for a Deployment
service.yaml # Template for a Service
values.yaml # Default configuration values
Helm makes it easy to reuse configurations across different projects and share your charts with others, providing a practical way to manage the complexity of Kubernetes applications.
What is Kustomize?
Now, let’s talk about Kustomize. Imagine Kustomize as a powerful customization tool for Kubernetes, a versatile toolkit designed to modify and adapt existing Kubernetes configurations. It provides a way to create variations of your deployment without having to rewrite or duplicate configurations. Think of it as having a set of advanced tools to tweak, fine-tune, and adapt everything you already have. Kustomize allows you to take a base configuration and apply overlays to create different variations for various environments, making it highly flexible for scenarios like development, staging, and production.
Kustomize works by applying patches and transformations to your base Kubernetes YAML files. Instead of duplicating the entire configuration for each environment, you define a base once, and then Kustomize helps you apply environment-specific changes on top. Imagine you have a basic configuration, and Kustomize is your stencil and spray paint set, letting you add layers of detail to suit different environments while keeping the base consistent. Here’s what a typical Kustomize project might look like:
The structure is straightforward: you have a base directory that contains your core configurations, and an overlays directory that includes different environment-specific customizations. This makes Kustomize particularly powerful when you need to maintain multiple versions of an application across different environments, like development, staging, and production, without duplicating configurations.
Kustomize shines when you need to maintain variations of the same application for multiple environments, such as development, staging, and production. This helps keep your configurations DRY (Don’t Repeat Yourself), reducing errors and simplifying maintenance. By keeping base definitions consistent and only modifying what’s necessary for each environment, you can ensure greater consistency and reliability in your deployments.
Helm vs Kustomize, different approaches
Helm uses templating to generate Kubernetes manifests. It takes your chart’s templates and values, combines them, and produces the final YAML files that Kubernetes needs. This templating mechanism allows for a high level of flexibility, but it also adds a level of complexity, especially when managing different environments or configurations. With Helm, the user must define various parameters in values.yaml files, which are then injected into templates, offering a powerful but sometimes intricate method of managing deployments.
Kustomize, by contrast, uses a patching approach, starting from a base configuration and applying layers of customizations. Instead of generating new YAML files from scratch, Kustomize allows you to define a consistent base once, and then apply overlays for different environments, such as development, staging, or production. This means you do not need to maintain separate full configurations for each environment, making it easier to ensure consistency and reduce duplication. Kustomize’s patching mechanism is particularly powerful for teams looking to maintain a DRY (Don’t Repeat Yourself) approach, where you only change what’s necessary for each environment without affecting the shared base configuration. This also helps minimize configuration drift, keeping environments aligned and easier to manage over time.
Ease of use
Helm can be a bit intimidating at first due to its templating language and chart structure. It’s like jumping straight onto a motorcycle, whereas Kustomize might feel more like learning to ride a bike with training wheels. Kustomize is generally easier to pick up if you are already familiar with standard Kubernetes YAML files.
Packaging and reusability
Helm excels when it comes to packaging and distributing applications. Helm charts can be shared, reused, and maintained, making them perfect for complex applications with many dependencies. Kustomize, on the other hand, is focused on customizing existing configurations rather than packaging them for distribution.
Integration with kubectl
Both tools integrate well with Kubernetes’ command-line tool, kubectl. Helm has its own CLI, helm, which extends kubectl capabilities, while Kustomize can be directly used with kubectl via the -k flag.
Declarative vs. Imperative
Kustomize follows a declarative mode, you describe what you want, and it figures out how to get there. Helm can be used both declaratively and imperatively, offering more flexibility but also more complexity if you want to take a hands-on approach.
Release history management
Helm provides built-in release management, keeping track of the history of your deployments so you can easily roll back to a previous version if needed. Kustomize lacks this feature, which means you need to handle versioning and rollback strategies separately.
CI/CD integration
Both Helm and Kustomize can be integrated into your CI/CD pipelines, but their roles and strengths differ slightly. Helm is frequently chosen for its ability to package and deploy entire applications. Its charts encapsulate all necessary components, making it a great fit for automated, repeatable deployments where consistency and simplicity are key. Helm also provides versioning, which allows you to manage releases effectively and roll back if something goes wrong, which is extremely useful for CI/CD scenarios.
Kustomize, on the other hand, excels at adapting deployments to fit different environments without altering the original base configurations. It allows you to easily apply changes based on the environment, such as development, staging, or production, by layering customizations on top of the base YAML files. This makes Kustomize a valuable tool for teams that need flexibility across multiple environments, ensuring that you maintain a consistent base while making targeted adjustments as needed.
In practice, many DevOps teams find that combining both tools provides the best of both worlds: Helm for packaging and managing releases, and Kustomize for environment-specific customizations. By leveraging their unique capabilities, you can build a more robust, flexible CI/CD pipeline that meets the diverse needs of your application deployment processes.
Helm and Kustomize together
Here’s an interesting twist: you can use Helm and Kustomize together! For instance, you can use Helm to package your base application, and then apply Kustomize overlays for environment-specific customizations. This combo allows for the best of both worlds, standardized base configurations from Helm and flexible customizations from Kustomize.
Use cases for combining Helm and Kustomize
Environment-Specific customizations: Use Kustomize to apply environment-specific configurations to a Helm chart. This allows you to maintain a single base chart while still customizing for development, staging, and production environments.
Third-Party Helm charts: Instead of forking a third-party Helm chart to make changes, Kustomize lets you apply those changes directly on top, making it a cleaner and more maintainable solution.
Secrets and ConfigMaps management: Kustomize allows you to manage sensitive data, such as secrets and ConfigMaps, separately from Helm charts, which can help improve both security and maintainability.
Final thoughts
So, which tool should you choose? The answer depends on your needs and preferences. If you’re looking for a comprehensive solution to package and manage complex Kubernetes applications, Helm might be the way to go. On the other hand, if you want a simpler way to tweak configurations for different environments without diving into templating languages, Kustomize may be your best bet.
My advice? If the application is for internal use within your organization, use Kustomize. If the application is to be distributed to third parties, use Helm.
We’re about to look into the fascinating world of Kubernetes Operators. But before we get to the main course, let’s start with a little appetizer to set the stage
A Quick Refresher on Kubernetes
You’ve probably heard of Kubernetes, right? It’s like a super-smart traffic controller for your containerized applications. These are self-contained environments that package everything your app needs to run, from code to libraries and dependencies. Imagine a busy airport where planes (your containers) are constantly taking off and landing. Kubernetes is the air traffic control system that makes sure everything runs smoothly, efficiently, and safely.
The Challenge. Managing Complex Applications
Now, picture this: You’re not just managing a small regional airport anymore. Suddenly, you’re in charge of a massive international hub with hundreds of flights, different types of aircraft, and complex schedules. That’s what it’s like trying to manage modern, distributed, cloud-native applications in Kubernetes manually. Especially when you’re dealing with stateful applications or distributed systems that require fine-tuned coordination, things can get overwhelming pretty quickly.
Enter the Kubernetes Operator. Your Application’s Autopilot
This is where Kubernetes Operators come in. Think of them as highly skilled pilots who know everything about a specific type of aircraft. They can handle all the complex maneuvers, respond to changing conditions, and ensure a smooth flight from takeoff to landing. That’s exactly what an Operator does for your application in Kubernetes.
What Exactly is a Kubernetes Operator?
Let’s break it down in simple terms:
Definition: An Operator is like a custom-built robot that extends Kubernetes’ abilities. It’s programmed to understand and manage a specific application’s entire lifecycle.
Analogy: Imagine you have a pet robot that knows everything about taking care of your house plants. It waters them, adjusts their sunlight, repots them when needed, and even diagnoses plant diseases. That’s what an Operator does for your application in Kubernetes.
Controller: The Operator’s logic is embedded in a Controller. This is essentially a loop that constantly checks the desired state versus the current state of your application and acts to reconcile any differences. If the current state deviates from what it should be, the Controller steps in and makes the necessary adjustments.
Key Components:
Custom Resource Definitions (CRDs): These are like new vocabulary words that teach Kubernetes about your specific application. They extend the Kubernetes API, allowing you to define and manage resources that represent your application’s needs as if Kubernetes natively understood them.
Reconciliation Logic: This is the “brain” of the Operator, constantly monitoring the state of your application and taking action to maintain it in the desired condition.
Why Do We Need Operators?
They’re Expert Multitaskers: Operators can handle complex tasks like installation, updates, backups, and scaling, all on their own.
They’re Lifecycle Managers: Just like how a good parent knows exactly what their child needs at different stages of growth, Operators understand your application’s needs throughout its lifecycle, adjusting resources and configurations accordingly.
They Simplify Things: Instead of you having to speak “Kubernetes” to manage your app, the Operator translates your simple commands into complex Kubernetes actions. They take Kubernetes’ declarative model to the next level by constantly monitoring and reconciling the desired state of your app.
They’re Domain Experts: Each Operator is like a specialist doctor for a specific type of application. They know all the ins and outs of how it should behave, handle its quirks, and optimize its performance.
The Perks of Using Operators
Fewer Oops Moments: By reducing manual tasks, Operators help prevent those facepalm-worthy human errors that can bring down applications.
More Time for Coffee Breaks: Okay, maybe not just coffee breaks, but automating repetitive tasks frees you up for more strategic work. Additionally, Operators integrate seamlessly with GitOps methodologies, allowing for full end-to-end automation of your infrastructure and applications.
Growth Without Growing Pains: Operators can manage applications at a massive scale without breaking a sweat. As your system grows, Operators ensure it scales efficiently and reliably.
Tougher Apps: With Operators constantly monitoring and adjusting, your applications become more resilient and recover faster from issues, often without any intervention from you.
Real-World Examples of Operator Magic
Database Whisperers: Operators can set up, configure, scale, and backup databases like PostgreSQL, MySQL, or MongoDB without you having to remember all those pesky command-line instructions. For instance, the PostgreSQL Operator can automate everything from provisioning to scaling and backup.
Messaging System Maestros: They can juggle complex messaging clusters, like Apache Kafka or RabbitMQ, handling partitions, replication, and scaling with ease.
Observability Ninjas: Take the Prometheus Operator, for example. It automates the deployment and management of Prometheus, allowing dynamic service discovery and gathering metrics without manual intervention.
Jack of All Trades: Really, any application with a complex lifecycle can benefit from having its own personal Operator. Whether it’s storage systems, machine learning platforms, or even CI/CD pipelines, Operators are there to make your life easier.
To see just how easy it is, here’s a simple YAML example to deploy Prometheus using the Prometheus Operator:
We’re defining a Prometheus custom resource (thanks to the Prometheus Operator).
It specifies how Prometheus should be deployed, including memory requests, storage, and alerting configurations.
The serviceMonitorSelector ensures that only services with specific labels (in this case, team: frontend) are monitored.
Storage is defined using persistent volumes, ensuring that Prometheus data is retained even if the pod is restarted.
This YAML configuration is just the beginning. The Prometheus Operator allows for more advanced setups, automating otherwise complex tasks like monitoring service discovery, setting up persistent storage, and integrating alert managers, all with minimal manual intervention.
Wrapping Up
So, there you have it! Kubernetes Operators are like having a team of expert, tireless assistants managing your applications. They automate complex tasks, understand your app’s specific needs, and keep everything running smoothly.
As Kubernetes evolves towards more self-healing and automated systems, Operators play a crucial role in driving that transformation. They’re not just a cool feature, they’re the backbone of modern cloud-native architectures.
So, why not give Operators a try in your next project? Who knows, you might just find your new favorite Kubernetes sidekick.
Kubernetes is a compelling platform for managing containerized applications but can be complex. One area where Kubernetes shines is its ability to scale applications based on demand. However, traditional scaling methods in Kubernetes might not always be the most efficient, especially when dealing with event-driven workloads. This is where KEDA (Kubernetes Event-Driven Autoscaling) comes into play.
What is KEDA?
KEDA stands for Kubernetes Event-Driven Autoscaling. It is an open-source component that allows Kubernetes to scale applications based on events. This means that instead of only scaling your applications based on metrics like CPU or memory usage, you can scale them based on specific events or external metrics such as the number of messages in a queue, the rate of requests to an endpoint, or custom metrics from various sources.
Key Features and Functionalities
Event-Driven Scaling: KEDA enables scaling based on the number of events that need to be processed, rather than just CPU or memory metrics.
Lightweight Component: KEDA is designed to be a lightweight addition to your Kubernetes cluster, ensuring it doesn’t interfere with other components.
Flexibility: It integrates seamlessly with Kubernetes’ Horizontal Pod Autoscaler (HPA), extending its functionality without overwriting or duplicating it.
Built-In Scalers: KEDA comes with over 50 built-in scalers for various platforms, including cloud services, databases, messaging systems, telemetry systems, CI/CD tools, and more.
Support for Multiple Workloads: It can scale various types of workloads, including deployments, jobs, and custom resources.
Scaling to Zero: KEDA allows scaling down to zero pods when there are no events to process, optimizing resource usage and reducing costs.
Extensibility: You can use community-maintained or custom scalers to support unique event sources.
Provider-Agnostic: KEDA supports event triggers from a wide range of cloud providers and products.
Azure Functions Integration: It allows you to run and scale Azure Functions in Kubernetes for production workloads.
Resource Optimization: KEDA helps build sustainable platforms by optimizing workload scheduling and scaling to zero when not needed.
Advantages of Using KEDA
Efficiency: By scaling based on actual events, KEDA ensures that your application only uses the resources it needs, improving efficiency and potentially reducing costs.
Flexibility: With support for a wide range of event sources and integration with HPA, KEDA provides a flexible scaling solution.
Simplicity: It simplifies the configuration of event-driven scaling in Kubernetes, abstracting the complexities of integrating different event sources.
Seamless Integration: KEDA works well with existing Kubernetes components and can be easily integrated into your current infrastructure.
Optimizing a Retail Application
Imagine you are managing an online retail application. During normal hours, traffic is relatively steady, but during sales events, the number of orders can spike dramatically. Here’s how KEDA can help:
Order Processing: Your application uses a message queue to handle order processing. Normally, the queue has a manageable number of messages, but during a sale, the number of messages can skyrocket.
Scaling with KEDA: KEDA can monitor the message queue and automatically scale the order processing service based on the number of messages. This ensures that as more orders come in, additional instances of the service are started to handle the load, preventing delays and improving customer experience.
Cost Management: Once the sale is over and the message count drops, KEDA will scale down the service, ensuring that you are not paying for unused resources.
Scaling to Zero: When there are no orders to process, KEDA can scale the order processing service down to zero pods, further reducing costs.
In a few words
KEDA is a powerful tool that brings the benefits of event-driven scaling to Kubernetes. Its ability to scale applications based on events makes it an ideal choice for dynamic workloads. By integrating with a variety of event sources and providing a simple yet flexible way to configure scaling, KEDA helps optimize resource usage, enhance performance, and manage costs effectively. Whether you’re running an e-commerce platform, processing data streams, or managing microservices, KEDA can help ensure your applications are always running efficiently.
In essence, KEDA is about making your applications responsive to real-world events, ensuring they are always ready to meet demand without wasting resources. It’s a valuable addition to any Kubernetes toolkit, offering a smarter, more efficient way to handle scaling.
In this guide, we’ll embark on a journey into the heart of Kubernetes, unraveling its essential concepts and demystifying its inner workings. Whether you’re a complete beginner or have dipped your toes into the container orchestration waters, fear not! We’ll break down the complexities into bite-sized, easy-to-digest pieces, ensuring you grasp the fundamentals with confidence.
What is Kubernetes, anyway?
Before we jump into the nitty-gritty, let’s quickly recap what Kubernetes is. Imagine you’re running a big restaurant. Kubernetes is like the head chef who manages the kitchen, making sure all the dishes are prepared correctly, on time, and served to the right tables. In the world of software, Kubernetes does the same for your applications, ensuring they run smoothly across multiple computers.
Now, let’s explore some key Kubernetes concepts:
1. Kubelet: The Kitchen Porter
The Kubelet is like the kitchen porter in our restaurant analogy. It’s a small program that runs on each node (computer) in your Kubernetes cluster. Its job is to make sure that containers are running in a Pod. Think of it as the person who makes sure each cooking station has all the necessary ingredients and utensils.
2. Pod: The Cooking Station
A Pod is the smallest deployable unit in Kubernetes. It’s like a cooking station in our kitchen. Just as a cooking station might have a stove, a cutting board, and some utensils, a Pod can contain one or more containers that work together.
Here’s a simple example of a Pod definition in YAML:
Containers are like the chef’s tools at each cooking station. They’re packaged versions of your application, including all the ingredients (code, runtime, libraries) needed to run it. In Kubernetes, containers live inside Pods.
4. Deployment: The Recipe Book
A Deployment in Kubernetes is like a recipe book. It describes how many replicas of a Pod should be running at any given time. If a Pod fails, the Deployment ensures a new one is created to maintain the desired number.
A Service in Kubernetes is like a waiter in our restaurant. It provides a stable “address” for a set of Pods, allowing other parts of the application to find and communicate with them. Even if Pods come and go, the Service ensures that requests are always directed to the right place.
Namespaces are like different kitchens in a large restaurant complex. They allow you to divide your cluster resources between multiple users or projects. This helps in organizing and isolating workloads.
7. ReplicationController: The Old-School Recipe Manager
The ReplicationController is an older way of ensuring a specified number of pod replicas are running at any given time. It’s like an old-school recipe manager that makes sure you always have a certain number of dishes ready. While it’s still used, Deployments are generally preferred for their additional features.
8. StatefulSet: The Specialized Kitchen Equipment
StatefulSets are used for applications that require stable, unique network identifiers, stable storage, and ordered deployment and scaling. Think of them as specialized kitchen equipment that needs to be set up in a specific order and maintained carefully.
9. Ingress: The Restaurant’s Front Door
An Ingress is like the front door of our restaurant. It manages external access to the services in a cluster, typically HTTP. Ingress can provide load balancing, SSL termination, and name-based virtual hosting.
10. ConfigMap: The Recipe Variations
ConfigMaps are used to store non-confidential data in key-value pairs. They’re like recipe variations that different dishes can use. For example, you might use a ConfigMap to store application configuration data.
Secrets are similar to ConfigMaps but are specifically designed to hold sensitive information, like passwords or API keys. They’re like the secret sauce recipes that only trusted chefs have access to.
And there you have it! These are some of the most important concepts in Kubernetes. Remember, mastering Kubernetes takes time and practice like learning to cook in a professional kitchen. Don’t worry if it seems overwhelming at first, keep experimenting, and you’ll get the hang of it.