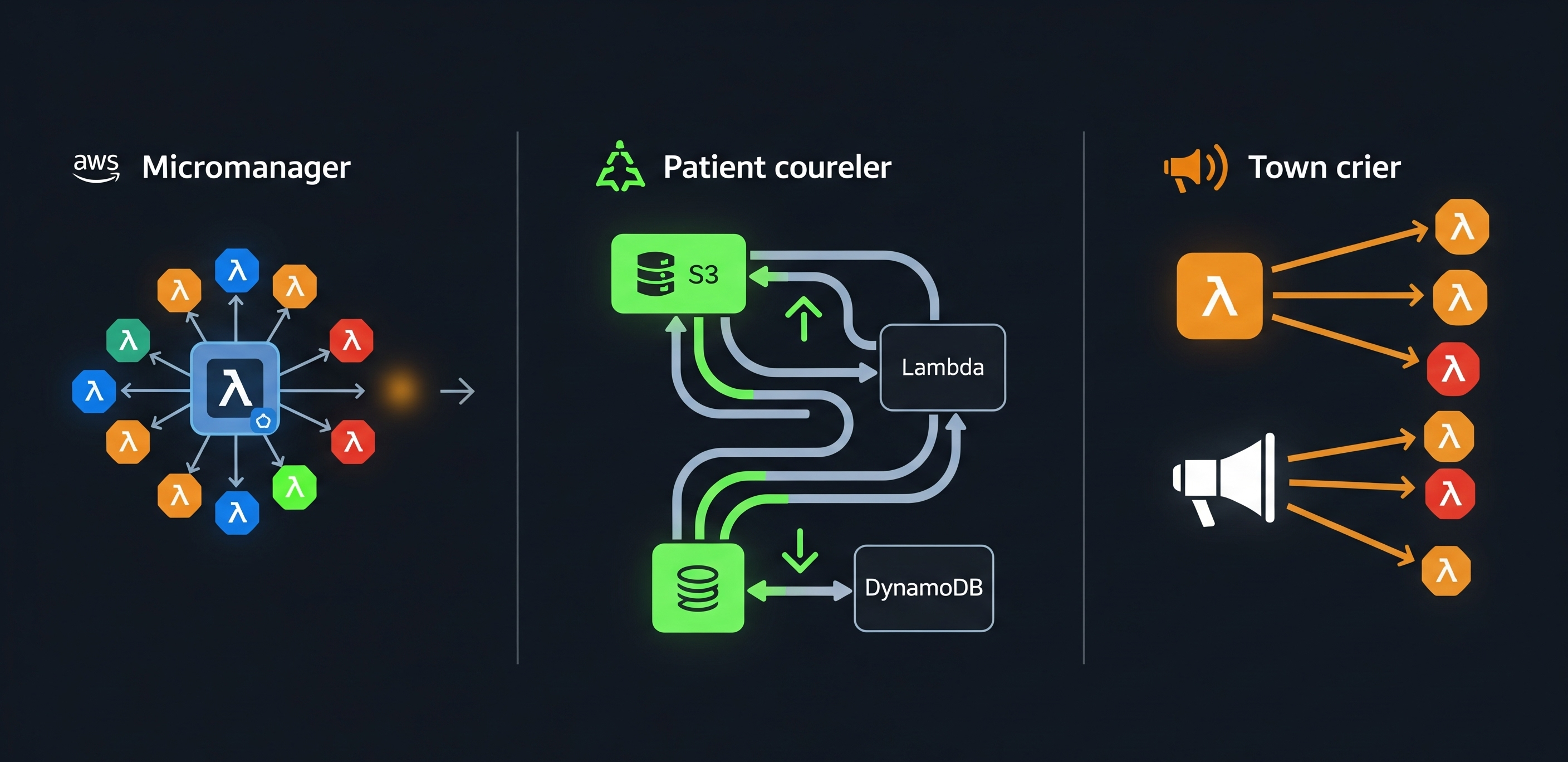
Getting traffic in and out of a Kubernetes cluster isn’t a magic trick. It’s more like running the city’s most exclusive nightclub. It’s a world of logistics, velvet ropes, bouncers, and a few bureaucratic tollbooths on the way out. Once you figure out who’s working the front door and who’s stamping passports at the exit, the rest is just good manners.
Let’s take a quick tour of the establishment.
A ninety-second tour of the premises
There are really only two journeys you need to worry about in this club.
Getting In: A hopeful guest (the client) looks up the address (DNS), arrives at the front door, and is greeted by the head bouncer (Load Balancer). The bouncer checks the guest list and directs them to the right party room (Service), where they can finally meet up with their friend (the Pod).
Getting Out: One of our Pods needs to step out for some fresh air. It gets an escort from the building’s internal security (the Node’s ENI), follows the designated hallways (VPC routing), and is shown to the correct exit—be it the public taxi stand (NAT Gateway), a private car service (VPC Endpoint), or a connecting tunnel to another venue (Transit Gateway).
The secret sauce in EKS is that our Pods aren’t just faceless guests; the AWS VPC CNI gives them real VPC IP addresses. This means the building’s security rules, Security Groups, route tables, and NACLs aren’t just theoretical policies. They are the very real guards and locked doors that decide whether a packet’s journey ends in success or a silent, unceremonious death.
Getting past the velvet rope
In Kubernetes, Ingress is the set of rules that governs the front door. But rules on paper are useless without someone to enforce them. That someone is a controller, a piece of software that translates your guest list into actual, physical bouncers in AWS.
The head of security for EKS is the AWS Load Balancer Controller. You hand it an Ingress manifest, and it sets up the door staff.
- For your standard HTTP web traffic, it deploys an Application Load Balancer (ALB). Think of the ALB as a meticulous, sharp-dressed bouncer who doesn’t just check your name. It inspects your entire invitation (the HTTP request), looks at the specific event you’re trying to attend (/login or /api/v1), and only then directs you to the right room.
- For less chatty protocols like raw TCP, UDP, or when you need sheer, brute-force throughput, it calls in a Network Load Balancer (NLB). The NLB is the big, silent type. It checks that you have a ticket and shoves you toward the main hall. It’s incredibly fast but doesn’t get involved in the details.
This whole operation can be made public or private. For internal-only events, the controller sets up an internal ALB or NLB and uses a private Route 53 zone, hiding the party from the public internet entirely.
The modern VIP system
The classic Ingress system works, but it can feel a bit like managing your guest list with a stack of sticky notes. The rules for routing, TLS, and load balancer behavior are all crammed into a single resource, creating a glorious mess of annotations.
This is where the Gateway API comes in. It’s the successor to Ingress, designed by people who clearly got tired of deciphering annotation soup. Its genius lies in separating responsibilities.
- The Platform team (the club owners) manages the Gateway. They decide where the entrances are, what protocols are allowed (HTTP, TCP), and handle the big-picture infrastructure like TLS certificates.
- The Application teams (the party hosts) manage Routes (HTTPRoute, TCPRoute, etc.). They just point to an existing Gateway and define the rules for their specific application, like “send traffic for app.example.com/promo to my service.”
This creates a clean separation of duties, offers richer features for traffic management without resorting to custom annotations, and makes your setup far more portable across different environments.
The art of the graceful exit
So, your Pods are happily running inside the club. But what happens when they need to call an external API, pull an image, or talk to a database? They need to get out. This is egress, and it’s mostly about navigating the building’s corridors and exits.
- The public taxi stand: For general internet access from private subnets, Pods are sent to a NAT Gateway. It works, but it’s like a single, expensive taxi stand for the whole neighborhood. Every trip costs money, and if it gets too busy, you’ll see it on your bill. Pro tip: Put one NAT in each Availability Zone to avoid paying extra for your Pods to take a cross-town cab just to get to the taxi stand.
- The private car service: When your Pods need to talk to other AWS services (like S3, ECR, or Secrets Manager), sending them through the public internet is a waste of time and money. Use
VPC endpoints instead. Think of this as a pre-booked black car service. It creates a private, secure tunnel directly from your VPC to the AWS service. It’s faster, cheaper, and the traffic never has to brave the public internet. - The diplomatic passport: The worst way to let Pods talk to AWS APIs is by attaching credentials to the node itself. That’s like giving every guest in the club a master key. Instead, we use
IRSA (IAM Roles for Service Accounts). This elegantly binds an IAM role directly to a Pod’s service account. It’s the equivalent of issuing your Pod a diplomatic passport. It can present its credentials to AWS services with full authority, no shared keys required.
Setting the house rules
By default, Kubernetes networking operates with the cheerful, chaotic optimism of a free-for-all music festival. Every Pod can talk to every other Pod. In production, this is not a feature; it’s a liability. You need to establish some house rules.
Your two main tools for this are Security Groups and NetworkPolicy.
Security Groups are your Pod’s personal bodyguards. They are stateful and wrap around the Pod’s network interface, meticulously checking every incoming and outgoing connection against a list you define. They are an AWS-native tool and very precise.
NetworkPolicy, on the other hand, is the club’s internal security team. You need to hire a third-party firm like Calico or Cilium to enforce these rules in EKS, but once you do, you can create powerful rules like “Pods in the ‘database’ room can only accept connections from Pods in the ‘backend’ room on port 5432.”
The most sane approach is to start with a default deny policy. This is the bouncer’s universal motto: “If your name’s not on the list, you’re not getting in.” Block all egress by default, then explicitly allow only the connections your application truly needs.
A few recipes from the bartender
Full configurations are best kept in a Git repository, but here are a few cocktail recipes to show the key ingredients.
Recipe 1: Public HTTPS with a custom domain. This Ingress manifest tells the AWS Load Balancer Controller to set up a public-facing ALB, listen on port 443, use a specific TLS certificate from ACM, and route traffic for app.yourdomain.com to the webapp service.
# A modern Ingress for your web application
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: webapp-ingress
annotations:
# Set the bouncer to be public
alb.ingress.kubernetes.io/scheme: internet-facing
# Talk to Pods directly for better performance
alb.ingress.kubernetes.io/target-type: ip
# Listen for secure traffic
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}]'
# Here's the TLS certificate to wear
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:us-east-1:123456789012:certificate/your-cert-id
spec:
ingressClassName: alb
rules:
- host: app.yourdomain.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: webapp-service
port:
number: 8080Recipe 2: A diplomatic passport for S3 access. This gives our Pod a ServiceAccount annotated with an IAM role ARN. Any Pod that uses this service account can now talk to AWS APIs (like S3) with the permissions granted by that role, thanks to IRSA.
# The ServiceAccount with its IAM credentials
apiVersion: v1
kind: ServiceAccount
metadata:
name: s3-reader-sa
annotations:
# This is the diplomatic passport: the ARN of the IAM role
eks.amazonaws.com/role-arn: arn:aws:iam::123456789012:role/EKS-S3-Reader-Role
---
# The Deployment that uses the passport
apiVersion: apps/v1
kind: Deployment
metadata:
name: report-generator
spec:
replicas: 1
selector:
matchLabels: { app: reporter }
template:
metadata:
labels: { app: reporter }
spec:
# Use the service account we defined above
serviceAccountName: s3-reader-sa
containers:
- name: processor
image: your-repo/report-generator:v1.5.2
ports:
- containerPort: 8080A short closing worth remembering
When you boil it all down, Ingress is just the etiquette you enforce at the front door. Egress is the paperwork required for a clean exit. In EKS, the etiquette is defined by Kubernetes resources, while the paperwork is pure AWS networking. Neither one cares about your intentions unless you write them down clearly.
So, draw the path for traffic both ways, pick the right doors for the job, give your Pods a proper identity, and set the tolls where they make sense. If you do, the cluster will behave, the bill will behave, and your on-call shifts might just start tasting a lot more like sleep.