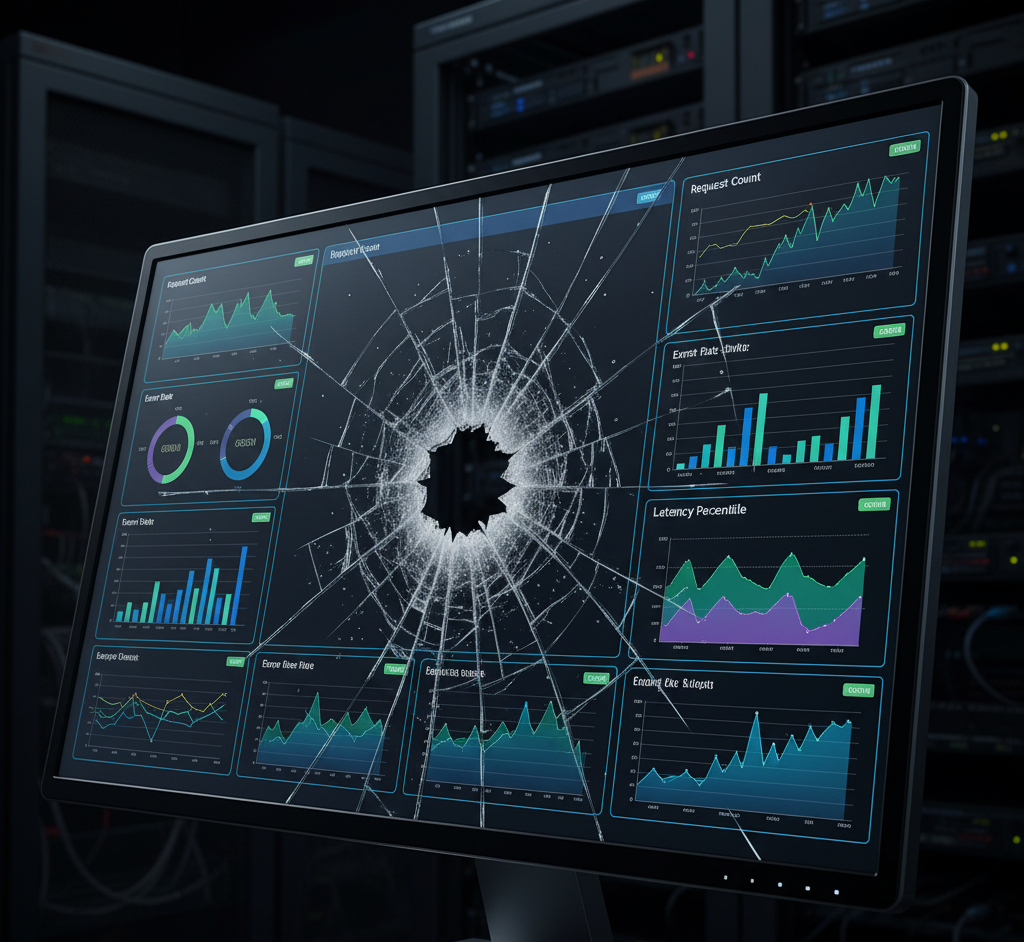
Every engineer loves a good dashboard. The vibrant graphs, the neat panels, the comforting glow of a wall of green lights. It’s the digital equivalent of a clean garage; it feels productive, organized, and ready for anything.
But let’s be honest: your dashboards are probably lying to you. They’re like a well-intentioned friend who tells you everything’s fine when you’ve got a smudge of chocolate on your nose and a bird nesting in your hair. They show you the surface, but hide the messy, inconvenient truth.
I learned this the hard way, at 2 a.m., as all the best lessons are learned. We were on-call when production latency went absolutely bonkers. I stared at four massive dashboards, each with a dozen panels of metrics swirling on my screen: CPU, memory, queue depth, disk I/O, HPA stats, all the usual suspects. I was a detective with a thousand clues but no insights, scrolling through what felt like a colorful, confusing kaleidoscope.
An hour of this high-octane confusion later, we discovered the culprit: a single, rogue DNS misconfiguration in a downstream service. The dashboards, those beautiful, useless liars, had all been glowing green.
This isn’t just bad luck. It’s a design flaw.
Designed for reports, not for war
Most dashboards are built for managers who need to glance at high-level metrics during a meeting, not for engineers trying to solve a full-blown crisis. We obsess over the shiny vanity metrics: request counts and 99th percentile latency, while the real demons, the retry storms and misbehaving clients, hide in the shadows.
Think of it like this: your dashboard is a doctor who only checks your height and weight. You might look great on paper, but your appendix could be about to explode. The surface looks fine, but the guts are in chaos.
The graveyard of abandoned dashboards
Have you ever wondered where old dashboards go to die? The answer is: nowhere. They simply get abandoned, like a pet you can no longer care for. Metrics get deprecated, panels start showing N/A, and alerts get muted permanently. They become relics of a bygone era, cluttering your screens with useless data and false promises. It’s the digital equivalent of that one junk drawer in your kitchen; it feels organized at a glance, but you know deep down it’s a monument to things you’ll never use again.
Too much signal, too much noise
Adding more panels doesn’t automatically give you better visibility. At scale, dashboards become a cacophony of white noise. You spend 30 minutes scanning, 5 minutes guessing, and 10 minutes restarting pods just to see if the blinking stops. That’s not observability; that’s panic dressed up as process.
Imagine trying to find your house key on a keychain with 500 different keys on it. You can see all of them, but you can’t find the one you need when you’re standing in the rain.
So, how do you fix it? You stop making art and start getting answers.
From Metrics to Methods
We stopped dumping metrics onto giant boards and created what we called “Runbooks with Graphs.” Instead of a hundred metrics per service, we had a handful per failure mode. It’s a fundamental shift in perspective.
Here’s an example of what that looked like:
failure_mode: API_response_slowdown
title: "API Latency Exceeding SLO"
hypothesis: "Is the database overloaded?"
metrics:
- name: "database_connections_count"
query: "sum(database_connections_total)"
- name: "database_query_latency_p99"
query: "histogram_quantile(0.99, rate(database_query_latency_seconds_bucket[5m]))"
runbook_link: "https://your-wiki.com/runbooks/api_latency_troubleshooting"This simple shift grouped our metrics by the why, not just the what.
Slaying Alert Fatigue
We took a good, hard look at our alerts and deleted 40% of them. Then, we rebuilt them from the ground up, basing them on symptoms, not raw metrics. This meant getting rid of things like this:
# BEFORE: A useless alert
- alert: HighCPULoad
expr: avg(cpu_usage_rate) > 0.8
for: 5m
labels:
severity: warning
annotations:
summary: "High CPU on instance {{ $labels.instance }}"And replacing it with something like this:
# AFTER: A meaningful, symptom-based alert
- alert: CustomerFacingSLOViolation
expr: rate(http_requests_total{status_code!~"2.."}) / rate(http_requests_total) > 0.1
for: 2m
labels:
severity: critical
annotations:
summary: "Too many failed API requests - SLO violated"
description: "The percentage of failed requests is over 10%."Suddenly, the team trusted the alerts again. When the pager went off, it actually meant something was wrong for the customers, not just a server having a bad day.
Blackhole checks and truth bombs
If dashboards can lie, you need tools that don’t. We added synthetic tests and end-to-end user simulations. These act like a secret shopper for your service, proving something is broken, whether your metrics look good or not.
Here’s a simple example of a synthetic check:
const axios = require('axios');
async function checkAPIMetrics() {
try {
const response = await axios.get('https://api.yourcompany.com/v1/health');
if (response.status !== 200) {
throw new Error(`Health check failed with status: ${response.status}`);
}
console.log('API is healthy.');
} catch (error) {
console.error('API health check failed:', error.message);
// Send alert to PagerDuty or Slack
}
}
checkAPIMetrics();Your internal metrics may say “OK,” but a synthetic user never lies about the customer’s experience.
The hard truth
Dashboards don’t solve outages. People do. They’re useful, but only if they’re maintained, contextual, and grounded in real-world operations. If your dashboards don’t reflect how failures actually unfold, they’re not observability, they’re art. And in the middle of a P1 incident, you don’t need art. You need answers.
This is the part where I’m supposed to give you a tidy, inspirational conclusion. Something about how we can all be better, more vigilant SREs. But let’s be realistic. The truth is, the world is full of dashboards that are just digital wallpaper, beautiful to look at, utterly useless in a crisis. They’re a collective delusion that makes us feel like we have everything under control, when in reality, we’re just scrolling through colorful confusion, hoping something will catch our eye.
So, before you build another massive, 50-panel dashboard, stop and ask yourself: is this going to help me at 2 a.m., with my coffee pot empty and a panic-stricken developer on the other end of the line? Or is it just another pretty lie to add to the collection?
How many of your dashboards are truly battle-ready? And which ones are just decorative?