There is a special kind of grief reserved for infrastructure that works fine. Nobody writes eulogies for the broken stuff; that gets deleted with enthusiasm. The painful goodbyes are for the things that still do their job every day, quietly, while the rest of the industry has already decided they belong in a museum. Your Ingress resources are in that category now. They route traffic, they terminate TLS, and they have not paged you in months. And they are, officially and by design, a dead end.
The Kubernetes project has been remarkably polite about this. Ingress is “frozen”, which is the standards body equivalent of moving someone to a nice farm upstate. No new features, no spec evolution, no fixes for the design decisions everyone now regrets. The replacement is called Gateway API, it reached general availability back in 2023, and it is one of those rare cases where the new thing is not just the old thing with more YAML. It actually fixes the organizational problem that made Ingress miserable, which, as we will see, was never really a technical problem at all.
The Ingress spec was always a rough draft
Here is the part of the story that usually gets left out. When Ingress shipped in 2015, the Kubernetes maintainers did not believe they had solved HTTP routing. They believed, correctly, that they had no idea what HTTP routing should look like, and they shipped a minimal spec on purpose. Host, path, backend service. That was essentially it. Everything else, the maintainers figured, could be handled by annotations until the community figured out what it actually wanted.
The community figured out what it wanted, all right. It wanted everything, and it wanted it via annotations.
If you have ever operated an nginx ingress controller in production, you know the genre. nginx.ingress.kubernetes.io/rewrite-target. nginx.ingress.kubernetes.io/canary-weight. nginx.ingress.kubernetes.io/configuration-snippet, which is the annotation equivalent of a hole in the wall that you push raw nginx config through and hope for the best. Traefik grew its own dialect. HAProxy grew another. At some point, the nginx controller alone supported well over a hundred proprietary annotations, each one a small confession that the spec underneath could not do the job.
The practical consequence is one that every platform engineer has lived. Your routing configuration is portable in theory and welded to your controller in practice. Migrating from nginx to anything else means translating a folklore of annotations by hand, and some of them have no translation, because they were never features of Kubernetes. They were features of one specific reverse proxy, smuggled in through a string field.
None of this makes Ingress bad design. It makes Ingress an honest admission, in 2015, that nobody agreed on what routing should look like. Gateway API is what happened after roughly eight years of arguing, when they finally agreed.
Three resources instead of one, and that is the whole upgrade
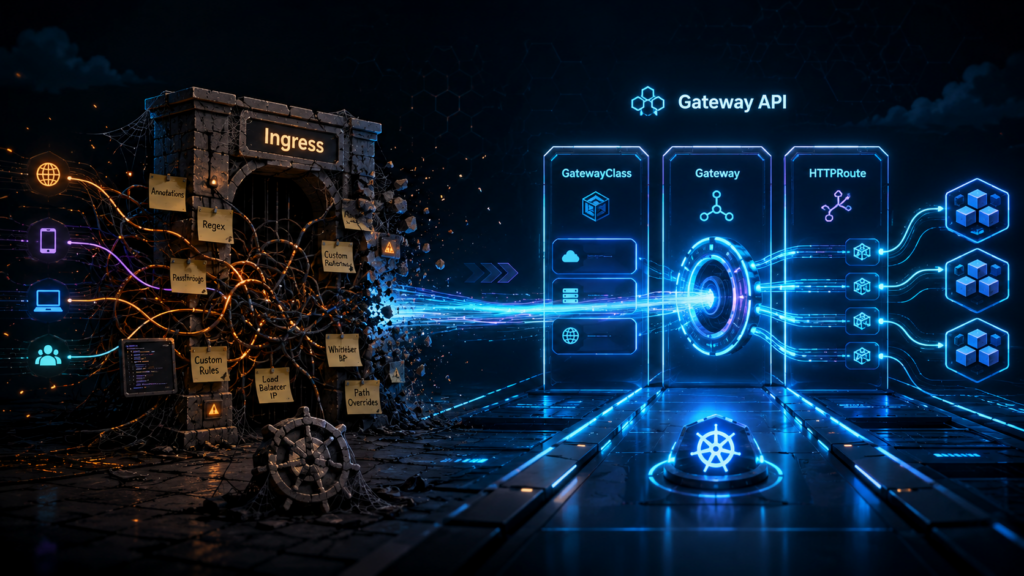
Gateway API replaces the single Ingress object with three, and before your YAML fatigue kicks in, stay with me, because the count is not the point. The ownership is.
GatewayClass is the template. It declares what kind of gateway infrastructure your cluster offers (Envoy, Cilium, or a cloud load balancer), and it gets written approximately once, by whoever runs the platform, and then mostly forgotten.
Gateway is a running instance of that template. It is the actual listener, the thing with an IP address and open ports, and it lives in an infrastructure namespace where application developers cannot poke it.
HTTPRoute is the routing rule. It says “traffic for this hostname and this path goes to this service”, and it lives in the application’s own namespace, right next to the Deployment it serves, owned by the team that owns the app.
That is the entire model. Three objects, three different owners, three different namespaces if you want them. Every interesting thing about Gateway API follows from that separation, which brings us to the actual argument.
The hallway belongs to the platform team, and the door belongs to the app team
Think about what an Ingress object actually is, organizationally. It is one resource that contains both infrastructure concerns (TLS certificates, load balancer behavior, controller tuning) and application concerns (which path goes to which service). One object, two very different audiences, and Kubernetes RBAC can only draw permission lines around whole objects.
So every organization running Ingress at scale ends up choosing between two bad options. Option one, the platform team owns all Ingress resources, and application teams file tickets to change a path rule, which is a magnificent way to turn a thirty-second change into a three-day wait. Option two, application teams own their Ingress resources, which means application teams can now set controller-level annotations, and somewhere in your cluster, there is a configuration snippet written by an intern in 2022 that nobody dares to remove. Both options are workarounds for the same flaw. The spec crammed two jobs into one object, and org charts do not bend that way.
Gateway API splits the object along exactly the line where your teams already split. The platform engineer provisions the Gateway in the infra namespace. They decide which ports are open, which TLS policy applies, and, crucially, which namespaces are allowed to attach routes to it. The application developer writes an HTTPRoute in their own namespace that says, in effect, “attach me to the gateway named external-web”. The route references the gateway by name; the gateway grants permission by policy. Cross-namespace routing is not a hack here, it is the core mechanic of the spec, with an explicit handshake on both sides.
If you read my past RBAC article, this will feel familiar, because it is the same principle wearing a different hat. Least privilege stopped being just about who can “kubectl delete” things and started applying to the network path itself. App teams get exactly the surface they need (their routes, their namespace) and nothing else. The platform team stops being a ticket-processing bottleneck and goes back to doing platform work. Nobody negotiates over annotations in a Slack thread at 6 p.m. on a Friday, which I am told does wonders for retention.
There is also a quieter benefit that only shows up in the postmortem. When routing rules live next to the application, the blast radius of a bad change is the application. When everything lives in one shared Ingress layer, a typo in one team’s path rule can take an unrelated team’s traffic with it. Separation of concerns is usually sold as elegance. In production, it is mostly sold as smaller incidents.
What Ingress made you beg your controller to do
Now for the features, briefly, because the features are genuinely less interesting than the reframe behind them.
Take canary deployments. With Ingress on nginx, weight-based traffic splitting means creating a second Ingress object, blessing it with ‘canary: “true”’ and ‘canary-weight: “10”’ annotations, and trusting that the controller interprets your strings correctly. With Gateway API, an HTTPRoute simply lists two backends with weights, 90 and 10, as ordinary structured fields. The API server validates them. Your canary rollout is now plain YAML instead of an incantation, and you did not have to install a service mesh to get it.
Header-based routing gets the same treatment. Routing requests with ‘x-beta-user: true’ to a different backend is a match condition in the spec, not a regex pasted into a controller-specific snippet. URL rewriting is a filter. Request mirroring, the trick where you copy live traffic to a new version without affecting real responses, is a filter too. Timeouts, header manipulation, traffic redirection, all first-class citizens with schemas.
Here is the reframe. None of these capabilities are new. Your reverse proxy could do all of this in 2016; reverse proxies are old and wise. What was missing was a portable way to ask for it. Under Ingress, every feature beyond host-and-path routing required learning the proprietary annotation dialect of whichever controller you happened to inherit, and your hard-won fluency in nginx annotations was worth exactly nothing the day someone migrated to Traefik. Gateway API moves those features into the spec itself, where they are typed, validated, and identical across implementations. The knowledge finally transfers. So do the manifests.
GatewayClass is the new vendor coupling point, and that is a better deal
Time for the honest section, because every article praising a new standard owes you one.
Gateway API does not eliminate vendor lock-in, and anyone telling you otherwise is selling a controller. The GatewayClass is where you commit. You pick Cilium, or Envoy Gateway, or Istio, or nginx-gateway-fabric, and from that moment your gateways run on that implementation’s machinery, with that implementation’s performance profile and that implementation’s extension features. Conformance across implementations is real but not absolute; the spec has core features everyone must support and extended ones they may.
What changed is the geometry of the coupling. With Ingress, the vendor dependency was smeared across your entire estate, hiding inside opaque annotation strings on every single routing object. You could not see it, measure it, or contain it; you discovered its true size on migration day, which is the worst possible day to discover anything. With Gateway API, the coupling is compressed into one object type. Everything above the GatewayClass (your routes, your matches, your filters, your weights) is portable standard YAML. Everything below it is the vendor’s problem. Swapping implementations becomes “change the GatewayClass and re-test”, not “translate three hundred annotations from one dialect to another and pray”.
The ecosystem, for the record, is not a science fair. Cilium ships a Gateway implementation on eBPF. Envoy Gateway is the CNCF’s straightforward Envoy packaging. Istio treats Gateway API as its preferred configuration surface these days. nginx-gateway-fabric exists for the sizable demographic that would like to keep nginx but lose the annotations. All of these run in production at companies whose outages would make the news.
You do not need to migrate everything to start
The best property of Gateway API for anyone with an existing cluster is that it demands nothing of your existing cluster. Gateway API and Ingress run side by side indefinitely. The controllers do not fight, the resources do not overlap, and your hundred working Ingress objects can keep working while you experiment two namespaces away.
The sensible entry point is not a migration project (migration projects are where enthusiasm goes to file status reports). It is one new service, or one feature branch, routed through an HTTPRoute while everything else stays put. You get a feel for the model, your platform team writes its first Gateway, and the canary feature gets a real audition on something low-stakes.
Whether your cluster is already prepared takes one command to find out.
kubectl get crds | grep gateway.networking.k8s.ioIf that returns a list of CRDs, the welcome mat is already out; managed offerings like GKE ship them preinstalled. If it returns nothing, the installation is a single manifest from the Gateway API releases page, and then the welcome mat is out.
Ingress will keep working for years. Frozen APIs in Kubernetes enjoy long, comfortable retirements, and nobody is coming to delete your manifests. But every new routing feature, every new controller capability, and increasingly every new piece of documentation is being written for the other API now. Borrowed time is still time. It is just no longer the kind you should be building on.