Spoiler: There is no single magic box. There is a tidy drawer of parts that click together so cleanly you stop missing the box.
The first time I asked a team to set up “Transit Gateway on Google Cloud,” I received the sort of polite silence you reserve for relatives who ask where you keep the fax machine. On AWS, you reach for Transit Gateway and call it a day. On Azure, you reach for Virtual WAN and its Virtual Hubs. On Google Cloud, you reach for… a shorter shopping list: one global VPC, Network Connectivity Center with VPC spokes when you need a hub, VPC Peering when you do not, Private Service Connect for producer‑consumer traffic, and Cloud Router to keep routes honest.
Once you stop searching for a product name and start wiring the right parts, transit on Google Cloud turns out to be pleasantly boring.
The short answer
- Inter‑VPC at scale → Network Connectivity Center (NCC) with VPC spokes
- One‑to‑one VPC connectivity → VPC Peering (non‑transitive)
- Private access to managed or third‑party services → Private Service Connect (PSC)
- Hybrid connectivity → Cloud Router + HA VPN or Interconnect with dynamic routing mode set to Global
That’s the toolkit most teams actually need. The rest of this piece is simply: where each part shines, where it bites, and how to string them together without leaving teeth marks.
How do the other clouds solve it?
- AWS: VPCs are regional. Transit Gateway acts as the hub; if you span regions, you peer TGWs. It is a well‑lit path and a single product name.
- Azure: VNets are regional. Virtual WAN gives you a global fabric with per‑region Virtual Hubs, optionally “secured” with an integrated firewall.
- Google Cloud: a VPC is global (routing table and firewalls are global, subnets remain regional). You do not need a separate “global transit” box to make two instances in different regions talk. When you outgrow simple, add NCC with VPC spokes for hub‑and‑spoke, PSC for services, and Cloud Router for dynamic routing.
Different philosophies, same goal. Google Cloud leans into a global network and small, specialized parts.
What a global VPC really means
A Google Cloud VPC gives you a global control plane. You define routes and firewall rules once, and they apply across regions; you place subnets per region where compute lives. That split is why multi‑region feels natural on GCP without an extra transit layer. Not everything is magic, though:
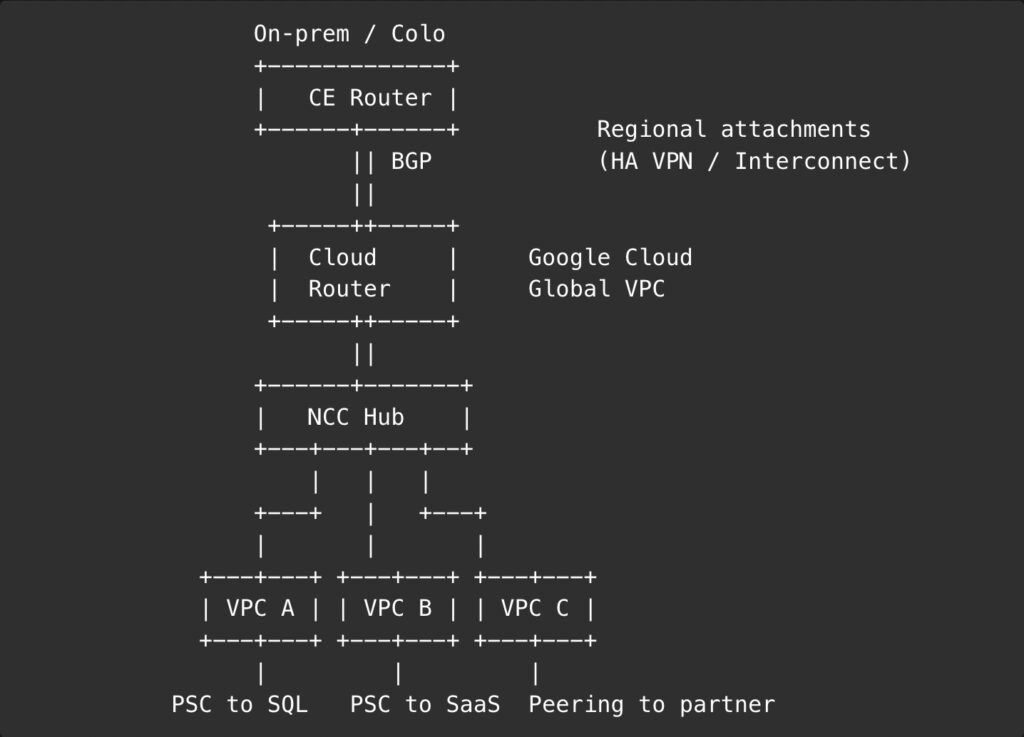
- Cloud Router, VPN, and Interconnect are regional attachments. You can and often should set dynamic routing mode to Global so learned routes propagate across the VPC, but the physical attachment still sits in a region.
- Global does not mean chaotic. IAM, firewall rules, hierarchical policies, and VPC Service Controls provide the guardrails you actually want.
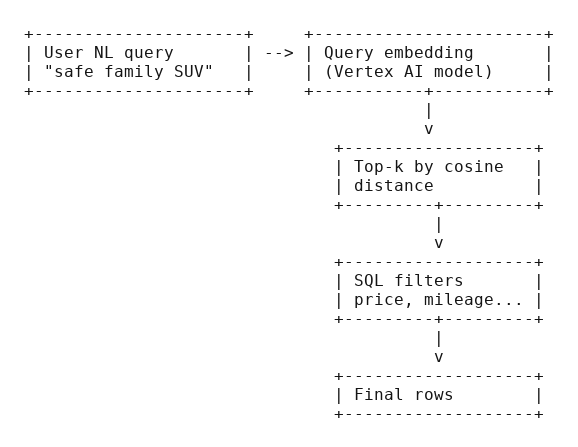
Choosing the right part
Network connectivity center with VPC spokes
Use it when you have many VPCs and want managed transit without building a mesh of N×N peerings. NCC gives you a hub‑and‑spoke model where spokes exchange routes through the hub, including hybrid spokes via Cloud Router. Think “default” once your VPC count creeps into the double digits.
Use when you need inter‑VPC transit at scale, clear centralization, and easy route propagation.
Avoid when you have only two or three VPCs that will never grow. Simpler is nicer.
VPC Peering
Use it for simple 1:1 connectivity. It is non‑transitive by design. If A peers with B and B peers with C, A does not automatically reach C. This is not a bug; it is a guardrail. If you catch yourself drawing triangles, take the hint and move to NCC.
Use when two VPCs need to talk, and that’s the end of the story.
Avoid when you need full‑mesh or centralized inspection.
Private Service Connect
Use it when a consumer VPC needs private access to a producer (managed Google service like Cloud SQL, or a third‑party/SaaS running behind a producer endpoint). PSC is not inter‑VPC transit; it is producer‑consumer plumbing with private IPs and tight control.
Use when you want “just the sauce” from a service without crossing the public internet.
Avoid when you are trying to stitch two application VPCs together. That is a job for NCC or peering.
Cloud Router with HA VPN or Interconnect
Use it for hybrid. Cloud Router speaks BGP and exchanges routes dynamically with your on‑prem or colo edge. Set dynamic routing to Global so routes learned in one region are known across the VPC. Remember that the attachments are regional; plan for redundancy per region.
Use when you want fewer static routes and less drift between environments.
Avoid when you expected a single global attachment. That is not how physics—or regions—work.
Three quick patterns
Multi‑region application in one VPC
One global VPC, regional subnets in us‑east1, europe‑west1, and asia‑east1. Instances talk across regions without extra kit. If the app grows into multiple VPCs per domain (core, data, edge), bring in NCC as the hub.
Mergers and acquisitions without a month of rewiring
Projects in Google Cloud are movable between folders and even organizations, subject to permissions and policy guardrails. That turns “lift and splice” into a routine operation rather than a quarter‑long saga. Be upfront about prerequisites: billing, liens, org policy, and compliance can slow a move; plan them, do not hand‑wave them.
Shared services with clean tenancy
Run shared services in a host project via Shared VPC. Attach service projects for each team. For an external partner, use VPC Peering or PSC, depending on whether they need network adjacency or just a service endpoint. If many internal VPCs need those shared bits, let NCC be the meeting place.
ASCII sketch of the hub
Pitfalls you can dodge
- Expecting peering to be transitive. It is not. If your diagram starts to look like spaghetti, stop and bring in NCC.
- Treating Cloud Router as global. It is regional. The routing mode can be Global; the attachment is not. Plan per‑region redundancy.
- Using PSC as inter‑VPC glue. PSC is for producer‑consumer privacy, not general transit.
- Forgetting DNS. Cross‑project and cross‑VPC name resolution needs deliberate configuration. Decide where you publish private zones and who can see them.
- Over‑centralizing inspection. The global VPC makes central stacks attractive, but latency budgets are still a thing. Place controls where the traffic lives.
Security that scales with freedom
A global VPC does not mean a free‑for‑all. The security model leans on identity and context rather than IP folklore.
- IAM everywhere for least privilege and clear ownership.
- VPC firewall rules with hierarchical policy for the sharp edges.
- VPC Service Controls for data perimeter around managed services.
- Cloud Armor and load balancers at the edge, where they belong.
The result is a network that is permissive where it should be and stubborn where it must be.
A tiny buying guide for your brain
- Two VPCs, done in a week → VPC Peering
- Ten VPCs, many teams, add partners next quarter → NCC with VPC spokes
- Just need private access to Cloud SQL or third‑party services → PSC
- Datacenter plus cloud, please keep routing sane → Cloud Router with HA VPN or Interconnect, dynamic routing Global
If you pick the smallest thing that works today and the most boring thing that still works next year, you will almost always land on the right square.
Where the magic isn’t
Transit Gateway is a great product name. It just happens to be the wrong shopping query on Google Cloud. You are not assembling a monolith; you are pulling the right pieces from a drawer that has been neatly labeled for years. NCC connects the dots, Peering keeps simple things simple, PSC keeps services private, and Cloud Router shakes hands with the rest of your world. None of them is glamorous. All of them are boring in the way electricity is boring when it works.
If you insist on a single giant box, you will end up using it as a hammer. Google Cloud encourages a tidier vice: choose the smallest thing that does the job, then let the global VPC and dynamic routing do the quiet heavy lifting. Need many VPCs to talk without spaghetti? NCC with spokes. Need two VPCs and a quiet life? Peering. Need only the sauce from Cloud SQL or a partner? PSC. Need the campus to meet the cloud without sticky notes of static routes? Cloud Router with HA VPN or Interconnect. Label the bag, not every screw.
The punchline is disappointingly practical. When teams stop hunting for a product name, they start shipping features. Incidents fall in number and in temperature. The network diagram loses its baroque flourishes and starts looking like something you could explain before your coffee cools.
So yes, keep admiring Transit Gateway as a name. Then close the tab and open the drawer you already own. Put the parts back in the same place when you are done, teach the interns what each one is for, and get back to building the thing your users actually came for. The box you were searching for was never the point; the drawer is how you move faster without surprises.